Enterprise
Auto Added by WPeMatico
Auto Added by WPeMatico
Last week at KubeCon and CloudNativeCon in Copenhagen, we saw an open source community coming together, full of vim and vigor and radiating positive energy as it recognized its growing clout in the enterprise world. Kubernetes, which came out of Google just a few years ago, has gained acceptance and popularity astonishingly rapidly — and that has raised both a sense of possibility and a boat load of questions.
At this year’s European version of the conference, the community seemed to be coming to grips with that rapid growth as large corporate organizations like Red Hat, IBM, Google, AWS and VMware all came together with developers and startups trying to figure out exactly what they had here with this new thing they found.
The project has been gaining acceptance as the defacto container orchestration tool, and as that happened, it was no longer about simply getting a project off the ground and proving that it could work in production. It now required a greater level of tooling and maturity that previously wasn’t necessary because it was simply too soon.
As this has happened, the various members who make up this growing group of users, need to figure out, mostly on the fly, how to make it all work when it is no longer just a couple of developers and a laptop. There are now big boy and big girl implementations and they require a new level of sophistication to make them work.
Against this backdrop, we saw a project that appeared to be at an inflection point. Much like a startup that realizes it actually achieved the product-market fit it had hypothesized, the Kubernetes community has to figure out how to take this to the next level — and that reality presents some serious challenges and enormous opportunities.
The Kubernetes project falls under the auspices of the Cloud Native Computing Foundation (or CNCF for short). Consider that at the opening keynote, CNCF director Dan Kohn was brimming with enthusiasm, proudly rattling off numbers to a packed audience, showing the enormous growth of the project.

Photo: Ron Miller
If you wanted proof of Kubernetes’ (and by extension cloud native computing’s) rapid ascension, consider that the attendance at KubeCon in Copenhagen last week numbered 4300 registered participants, triple the attendance in Berlin just last year.
The hotel and conference center were buzzing with conversation. Every corner and hallway, every bar stool in the hotel’s open lobby bar, at breakfast in the large breakfast room, by the many coffee machines scattered throughout the venue, and even throughout the city, people chatted, debated and discussed Kubernetes and the energy was palpable.
David Aronchick, who now runs the open source Kubeflow Kubernetes machine learning project at Google, was running Kubernetes in the early days (way back in 2015) and he was certainly surprised to see how big it has become in such a short time.
“I couldn’t have predicted it would be like this. I joined in January, 2015 and took on project management for Google Kubernetes. I was stunned at the pent up demand for this kind of thing,” he said.
Yet there was great demand, and with each leap forward and each new level of maturity came a new set of problems to solve, which in turn has created opportunities for new services and startups to fill in the many gaps. As Aparna Sinha, who is the Kubernetes group product manager at Google, said in her conference keynote, enterprise companies want some level of certainty that earlier adopters were willing to forego to take a plunge into the new and exciting world of containers.

Photo: Cloud Native Computing Foundation
As she pointed out, for others to be pulled along and for this to truly reach another level of adoption, it’s going to require some enterprise-level features and that includes security, a higher level of application tooling and a better overall application development experience. All these types of features are coming, whether from Google or from the myriad of service providers who have popped up around the project to make it easier to build, deliver and manage Kubernetes applications.
Sinha says that one of the reasons the project has been able to take off as quickly as it has, is that its roots lie in a container orchestration tool called Borg, which the company has been using internally for years. While that evolved into what we know today as Kubernetes, it certainly required some significant repackaging to work outside of Google. Yet that early refinement at Google gave it an enormous head start over an average open source project — which could account for its meteoric rise.
“When you take something so well established and proven in a global environment like Google and put it out there, it’s not just like any open source project invented from scratch when there isn’t much known and things are being developed in real time,” she said.
One thing everyone seemed to recognize at KubeCon was that in spite of the head start and early successes, there remains much work to be done, many issues to resolve. The companies using it today mostly still fall under the early adopter moniker. This remains true even though there are some full blown enterprise implementations like CERN, the European physics organization, which has spun up 210 Kubernetes clusters or JD.com, the Chinese Internet shopping giant, which has 20K servers running Kubernetes with the largest cluster consisting of over 5000 servers. Still, it’s fair to say that most companies aren’t that far along yet.

Photo: Ron Miller
But the strength of an enthusiastic open source community like Kubernetes and cloud native computing in general, means that there are companies, some new and some established, trying to solve these problems, and the multitude of new ones that seem to pop up with each new milestone and each solved issue.
As Abby Kearns, who runs another open source project, the Cloud Foundry Foundation, put it in her keynote, part of the beauty of open source is all those eyeballs on it to solve the scads of problems that are inevitably going to pop up as projects expand beyond their initial scope.
“Open source gives us the opportunity to do things we could never do on our own. Diversity of thought and participation is what makes open source so powerful and so innovative,” she said.
It’s worth noting that several speakers pointed out that diversity of thought also required actual diversity of membership to truly expand ideas to other ways of thinking and other life experiences. That too remains a challenge, as it does in technology and society at large.
In spite of this, Kubernetes has grown and developed rapidly, while benefiting from a community which so enthusiastically supports it. The challenge ahead is to take that early enthusiasm and translate it into more actual business use cases. That is the inflection point where the project finds itself, and the question is will it be able to take that next step toward broader adoption or reach a peak and fall back.
Powered by WPeMatico
Ever since Google created Kubernetes as an open source container orchestration tool, it has seen it blossom in ways it might never have imagined. As the project gains in popularity, we are seeing many adjunct programs develop. Today, Google announced the release of version 0.1 of the Kubeflow open source tool, which is designed to bring machine learning to Kubernetes containers.
While Google has long since moved Kubernetes into the Cloud Native Computing Foundation, it continues to be actively involved, and Kubeflow is one manifestation of that. The project was only first announced at the end of last year at Kubecon in Austin, but it is beginning to gain some momentum.
David Aronchick, who runs Kubeflow for Google, led the Kubernetes team for 2.5 years before moving to Kubeflow. He says the idea behind the project is to enable data scientists to take advantage of running machine learning jobs on Kubernetes clusters. Kubeflow lets machine learning teams take existing jobs and simply attach them to a cluster without a lot of adapting.
With today’s announcement, the project begins to move ahead, and according to a blog post announcing the milestone, brings a new level of stability, while adding a slew of new features that the community has been requesting. These include Jupyter Hub for collaborative and interactive training on machine learning jobs and Tensorflow training and hosting support, among other elements.
Aronchick emphasizes that as an open source project you can bring whatever tools you like, and you are not limited to Tensorflow, despite the fact that this early version release does include support for Google’s machine learning tools. You can expect additional tool support as the project develops further.
In just over 4 months since the original announcement, the community has grown quickly with over 70 contributors, over 20 contributing organizations along with over 700 commits in 15 repositories. You can expect the next version, 0.2, sometime this summer.
Powered by WPeMatico
As companies turn increasingly to containerization, it creates challenges in terms of monitoring each individual container and the impact on the underlying application. This is particularly difficult because of the ephemeral nature of containers, which can exist for a very short time. Datadog introduced a container map product today that could help by bringing visualization to bear on the problem.
“With his announcement, what we are doing is introducing a container map to show you all of the containers across your system,” Ilan Rabinovitch, VP of Product Management at Datadog told TechCrunch. This could enable customers to see every container at any given time, organize them into groups based on tags, then drill-down to see what’s happening within each one.
The company makes use of tags and metadata to identify the different parts of the containers and their relationship to one another and the underlying infrastructure. The tool monitors containers much like any other entity in Datadog.
“Just as the host map does with individual instances, the container map enables you to easily group, filter, and inspect your containers using metadata such as services, availability zones, roles, partitions, or any other dimension you like,” the company wrote in a blog post introducing the new feature.
While Datadog won’t help a company directly remediate a problem as it avoids having write access to a company’s systems, the customer can use Web hooks or a serverless trigger like an Amazon Lambda function to invoke some sort of action should certain conditions be met that could compromise or break the application.
The company is simply acting as a third party watching to make sure the containers all behave properly. “We trust Kubernetes to do what it should do. But when something breaks, you need to be able to understand what happened, and Kubernetes is not designed to do this,” Rabinovitch said. The new map features provides that missing visibility into the container system and lets users drill down inside individual containers to pinpoint the source of a problem.
Powered by WPeMatico
As SoundHound looks to leverage its ten-plus years of experience and data to create a voice recognition tool that companies can bake into any platform, it’s raising another big $100 million round of funding to try to make its Houndify platform a third neutral option compared to Alexa and Google Assistant.
While Amazon works to get developers to adopt Alexa, SoundHound has been collecting data since it started as an early mobile app for the iPhone and Android devices. That’s given it more than a decade of data to work with as it tries to build a robust audio recognition engine and tie it into a system with dozens of different queries and options that it can tie to those sounds. The result was always a better SoundHound app, but it’s increasingly started to try to open up that technology to developers and show it’s more powerful (and accurate) than the rest of the voice assistants on the market — and get them to use it in their services.
“We launched [Houndify] before Google and Amazon,” CEO Keyvan Mohajer said. “Obviously, good ideas get copied, and Google and Amazon have copied us. Amazon has the Alexa fund to invest in smaller companies and bribe them to adopt the Alexa Platform. Our reaction to that was, we can’t give $100 million away, so we came up with a strategy which was the reverse. Instead of us investing in smaller companies, let’s go after big successful companies that will invest in us to accelerate Houndify. We think it’s a good strategy. Amazon would be betting on companies that are not yet successful, we would bet on companies that are already successful.”
This round is all coming in from strategic investors. Part of the reason is that taking on these strategic investments allows SoundHound to capture important partnerships that it can leverage to get wider adoption for its technology. The companies investing, too, have a stake in SoundHound’s success and will want to get it wherever possible. The strategic investors include Tencent Holdings Limited, Daimler AG, Hyundai Motor Company, Midea Group, and Orange S.A. SoundHound already has a number of strategic investors that include Samsung, NVIDIA, KT Corporation, HTC, Naver, LINE, Nomura, Sompo, and Recruit. It’s a ridiculously long list, but again, the company is trying to get that technology baked in wherever it can.
So it’s pretty easy to see what SoundHound is going to get out of this: access to China through partners, deeper integration into cars, as well as increased expansion to other avenues through all of its investors. Mohajer said the company could try to get into China on its own (or ignore it altogether), but there has been a very limited number of companies that have had any success there whatsoever. Google and Facebook, two of the largest technology companies in the world, are not on that list of successes.
“China is a very important market, it’s very big and has a lot of potential, and it’s growing,” Mohajer said. “You can go to Canada without having to rethink a big strategy, but China is so different. We saw even companies like Google and Facebook tried to do that and didn’t succeed. When those bigger companies didn’t succeed, it was a signal to us that strategy wouldn’t work. [Tencent] was looking at the space and they saw we have the best technology in the world. They appreciated it and were respectful, they helped us get there. We looked at so many partners and [Tencent and Midea Group] were the ones that worked out.”
The idea here is that developers in all sorts of different markets — whether that’s cars or apps — will want to have some element of voice interaction. SoundHound is betting that companies like Daimler will want to control the experience in their cars, and not be saying “Alexa” whenever they want to make a request while driving. Instead, it may come down to something as simple as a wake word that could change the entire user experience, and that’s why SoundHound is pitching Houndify as a flexible and customizable option that isn’t demanding a brand on top of it.
SoundHound still does have its stable of apps. The original SoundHound app is around, though those features are also baked into Hound, its main consumer app. That is more of a personal assistant-style voice recognition service where you can string together a sentence of as many as a dozen parameters and get a decent search result back. It’s more of a party trick than anything else, but it is a good demonstration of the technical capabilities SoundHound has as it looks to embed that software into lots of different pieces of hardware and software.
SoundHound may have raised a big round with a fresh set of strategic partners, but that certainly doesn’t mean it’s a surefire bet. Amazon is, after all, one of the most valuable companies in the world and Alexa has proven to be a very popular platform, even if it’s mostly for nominal requests and listening to music (and party tricks) at this point. SoundHound is going to have to convince companies — small and large — to bake in its tools, rather than go with massive competitors like Amazon with pockets deep enough to buy a whole grocery chain.
“We think every company is going to need to have a strategy in voice AI, jus like ten years ago everyone needed a mobile strategy,” Mohajer said. “Everyone should think about it. There aren’t many providers, mainly because it takes a long time to build the core technology. It took us 12 years. To Houndify everything we need to be global, we need to support all the main languages and regions in the world. We built the technology to be language independent, but there’s a lot of resources and execution involved.”
Powered by WPeMatico
Kubernetes, the open source container orchestration tool, does a great job of managing a single cluster, but Upbound, a new Seattle-based startup wants to extend this ability to manage multiple Kubernetes clusters across multi-cloud environment. It’s a growing requirement as companies deploy ever-larger numbers of clusters and choose a multi-vendor approach to cloud infrastructure services.
Today, the company announced a $9 million Series A investment led by GV (formerly Google Ventures) along with numerous unnamed angel investors from the cloud-native community. As part of the deal, GV’s Dave Munichiello will be joining the company board of directors.
It’s important to note that the company is currently working on the product and could be a year away from a release, but the vision is certainly compelling. As Upbound CEO and founder Bassam Tabbara says, his company’s solution could allow customers to run, scale and optimize their workloads across clusters, regions and clouds as a single entity.
That level of control could enable them to set rules and policies across those clusters and clouds. For example, a customer might control costs by creating a rule to find the cloud with lowest cost for processing a given job, or provide failover control across regions and clouds — all automatically. It would provide the general ability to have highly granular control across multiple environments that isn’t really possible now, Tabbara explained.
That vision of enterprise portability is certainly something that caught the eye of GV’s Munichiello. “Upbound presents a credible approach to multi-cloud computing built on the success of Kubernetes, and as a response to the growing enterprise demand for hybrid and multi-cloud environments,” he said in a statement.
Companies are working with multiple Kubernetes clusters today. As an example, CERN, the European physics organization is running 210 clusters. JD.com, the Chinese shopping site has over 20,000 servers running Kubernetes. The largest cluster is made up of 5000 servers. As these projects scale, they require a tool to help manage their workloads across these larger environments.
The company’s founder isn’t new to cloud-native computing or open source. Tabbara was part of the team responsible for producing the open source project, Rook, an offshoot of Kubernetes and a Cloud Native Computing Foundation Sandbox project. Rook helps orchestrate distributed storage systems running in cloud native environments in a similar way that Kubernetes does for containerized environments. That project provided some of the ground work for what Upbound is trying to do on a broader scale beyond pure storage.
The computing world is suddenly all about abstraction. We started with virtual machines, which allowed you take an individual server and make it into multiple virtual machines. That led to containers, which could take the same machine in let you launch hundreds of containers. Kubernetes is an open source container orchestration tool that has rapidly gained acceptance by allowing operations to treat a cluster of Kubernetes nodes as a single entity, making it much easier to launch and manage containers.
Upbound launched last Fall and currently has 8 employees, but Tabbara says they are actively seeking new engineers. The nature of their business is about distributed workloads and he says the workforce will be similar. They won’t have to work in Seattle. He says the plan is to use and contribute to open source whenever possible and to open source parts of the product when it’s available.
Powered by WPeMatico
Cisco just announced an agreement to acquire Accompany, which uses artificial intelligence to build databases of people and relationships at companies.
Founder and CEO Amy Chang has compared the product to a digital chief of staff or personal assistant, giving executives the context they need before conversations and meetings. Cisco plans to incorporate Accompany technology into its collaboration products, for example by introducing company and individual profiles into Webex meetings.
Cisco says it will pay $270 million in cash and stock in the deal.
The company probably didn’t have to search too hard to find Accompany, since Chang (who previously served as the head of product for Google’s ad measurement and reporting) has been on Cisco’s board of directors since October 2016. As part of the transaction, she’s resigning from the board, effective immediately.
In addition, Chang will be taking over the company’s Collaboration Technology Group. Rowan Trollope, who currently leads the collaboration group, is departing to become CEO at cloud software company Five9.
“Amy has proven to be an effective and innovative leader through her years as an entrepreneur, an engineer, and CEO, and I couldn’t be more pleased to have her and the Accompany team join Cisco,” said Cisco chairman and CEO Chuck Robbins in the announcement. “Together, we have a tremendous opportunity to further enhance AI and machine learning capabilities in our collaboration portfolio and continue to create amazing collaboration experiences for customers.”
According to Crunchbase, Accompany has raised around $40 million in funding from investors including CRV, Cowboy Ventures, Iconiq Capital and Ignition Partners.
Cisco also announced today that it’s selling off some of its NDS video assets.
Powered by WPeMatico
Workplace, the more secure, closed enterprise version of Facebook that competes against the likes of Slack, Microsoft Teams and Hipchat as a platform for employees to communicate and work on things together, says that it today has tens of thousands of organisations using its platform.
Now to pick up more, and to bring more of customers into the paid premium tier of Workplace, Facebook is announcing a couple of new developments at F8.
First, it’s expanding the premium tier of the service with several more integrations — apps that it says have been the most requested by the “tens of thousands” of organizations using Workplace — including Jira, Sharepoint, and SurveyMonkey, bringing the total now to just over 50. And second, Facebook is now taking applications for app developers who want to integrate with the platform.
The latter is a significant shift: up to now, Facebook had been handpicking third-party integrations itself.
The new apps that are being announced today roughly fall into three categories, as outlined by Facebook. Those that let users share information; those that let users get daily summaries; and those that let users speed up data entry and data queries by way of bots.
New integrations for JIRA, Cornerstone OnDemand and Medallia allow users to bring in previews of content from these apps so that they can discuss them in Workplace. Users of Sharepoint from Microsoft can now also share folders from that into Workplace groups.

Meanwhile, users of SurveyMonkey, Hubspot, Marketo, Vonage and Zoom can get notifications from those apps to update on how campaigns and other work is running within those services.
Lastly, Workplace is now bringing bots into its platform to help manage queries from apps outside of it. A new integration with ADP for example will let employees start a chat with it to request a payslip, book and get updates on vacation time and more. Others that are launching bots for querying their apps include AdobeSign, Kronos, Smartsheet and Workday.
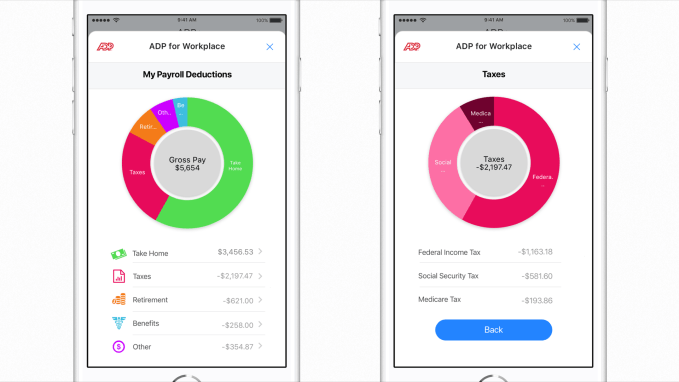
The bigger idea behind today’s app expansion, and opening up the platform to more users, is to continue to expand the usefulness of Workplace.
It’s been a fairly methodical journey, the antithesis of “move fast and break things,” Facebook’s (sometimes notorious) mantra.
When the service made its official debut in closed beta back in January 2015 (when it was called Facebook at Work), it was little more than a basic version of Facebook that could be used in a more closed environment, a little like a closed Facebook Group.
It rebranded to Workplace when it officially left its closed beta in October 2016, but that was nearly two years later.
The subsequent addition of apps and features like chat (which came a year after that) have also been very gradual. Even today, there is a big gulf between the 50 or so apps that you can use with Workplace and the 1,400+ that are available on a platform like Slack.
Julien Codorniou, who leads the Workplace effort at Facebook, describes the company’s slower approach to adding apps and features as very intentional.
“We don’t need 1,000 apps on Workplace,” he said. “Our customers ask for an application like Sharepoint or Jira. We wanted to keep the integrations meaningful, and to keep them beautiful in the news feed.”
In 2017 Workplace snapped up retail giant Walmart as a customer, and in a way that deal is indicative of how Workplace has positioned itself as a product.
Facebook is targeting businesses that have a mix of employees that range from those who sit at desks to those who never sit at a desk. And as a result, it wants to keep the number of apps and IT noise low to avoid putting off those users.
“We try to connect people who have never had access to software as a service by making products like ServiceNow easy to use,” Codorniou said.
So there is a common touch, but it only goes so far.
Ultimately, the full set of app integrations is only available for those users who are on the premium tier of the product. Pricing is $3 per active user, per month up to 5,000 users. More users are negotiated with Facebook. Those who are standard users get a much more limited range of apps, including Box, OneDrive and Dropbox and RSS. Codorniou would not comment on whether Facebook had plans to add more apps into the free tier.

Powered by WPeMatico
It’s tough being part of IT Ops these days. Your company could be operating across public and private clouds, and in many cases, an internal datacenter too. Meanwhile your developers are generating more code ever faster. ScienceLogic wants to help with it latest release, ScienceLogic SL1.
As company CEO Dave Link sees, we are seeing this vast confluence of technology influences coming together very quickly. He says the goal with this release is nothing less than a comprehensive, full-stack view of how an application is behaving, and how the different pieces that make up and connect to that application could be affecting its performance.
“Every CIO wants to know the health of their mission critical business services and only way to see that is to see through the entire stack,” Link said.
Part of the problem of course is the sheer volume of information. As that increases, it becomes nearly impossible for humans, even the most highly skilled among us, to keep up and understand what particular element may be causing an application to misbehave. That problem is exacerbated further by the speed at which developers are generating new code.
Murali Nemani, CMO at ScienceLogic, says that’s where artificial intelligence and machine learning come into play. “Part of the problem is that if businesses are moving at machine speed in terms of their capability to innovate, the big challenge is how do you get operations to keep up with what developers are creating,” Nemani asked.
The machine learning aspect of the platform enables companies to begin automating solutions for some of the more common problems, while directing the more unusual ones to humans on the operations team. They rely on the AI tools produced by others, rather than trying to develop that part of the solution themselves. “If an application is performing poorly, we can diagnose which part is the problem child, then feed this information to AI/ML engines like Google TensorFlow or IBM Watson and see pattern recognition. That’s the way we achieve machine speed,” Nemani explained.
Link says they do this by looking at the problem holistically and giving operations a full view of the application to track down the problem behavior and fix it. “We look at all the layers when we think of a service view: security, systems, network, OS, infrastructure then the application layer (database and application tier). We then contextualize all of those elements into one service view, so [the customer has] the most efficient view of what’s happening in real time,” Link said.
The product being announced publicly today has been early Beta up to now and will be generally available on July 25th.
Powered by WPeMatico
CoreOS, the Linux distribution and container management startup Red Hat acquired for $250 million earlier this year, today announced the Operator Framework, a new open source toolkit for managing Kubernetes clusters.
CoreOS first talked about operators in 2016. The general idea here is to encode the best practices for deploying and managing container-based applications as code. “The way we like to think of this is that the operators are basically a picture of the best employee you have,” Red Hat OpenShift product manager Rob Szumski told me. Ideally, the Operator Framework frees up the operations team from doing all the grunt work of managing applications and allows them to focus on higher-level tasks. And at the same time, it also removes the error-prone humans from the process since the operator will always follow the company rulebook.

“To make the most of Kubernetes, you need a set of cohesive APIs to extend in order to service and manage your applications that run on Kubernetes,” CoreOS CTO Brandon Philips explains in today’s announcement. “We consider Operators to be the runtime that manages this type of application on Kubernetes.”
As Szumski told me, the CoreOS team developed many of these best practices in building and managing its own Tectonic container platform (and from the community that uses it). Once written, the operators watch over the Kubernetes cluster and can handle upgrades, for example, and when things go awry, the can react to failures within milliseconds.
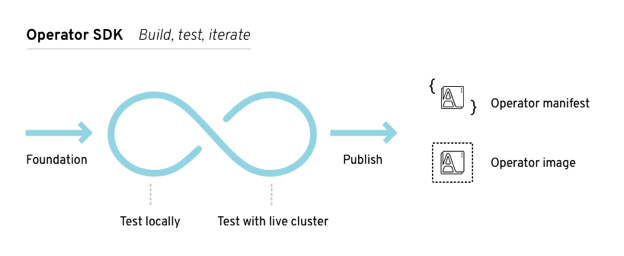
The overall Operator Framework consists of three pieces: an SDK for building, testing and packaging the actual operator, the Operator Lifecycle Manager for deploying the operator to a Kubernetes cluster and managing them, and the Operator Metering tool for metering Kubernetes users for enterprises that need to do chargebacks or that want to charge their customers based on usage.
The metering tool doesn’t quite seem to fit into the overall goal here, but as Szumski told me, it’s something a lot of businesses have been looking for and CoreOS actually argues that this is a first for Kubernetes.
Today’s CoreOS/Red Hat announcement only marks the start of a week that’ll likely see numerous other Kubernetes-related announcements. That’s because the Cloud Native Computing Foundation is its KubeCon developer conference in the next few days and virtually every company in the container ecosystem will attend the event and have some kind of announcements.
Powered by WPeMatico
When trying to figure out what to do after an extensive career at Google, Motorola, and Flipkart, Punit Soni decided to spend a lot of time sitting in doctors’ offices to figure out what to do next.
It was there that Soni said he figured out one of the most annoying pain points for doctors in any office: writing down notes and documentation. That’s why he decided to start Suki — previously Robin AI — to create a way for doctors to simply start talking aloud to take notes when working with patients, rather than having to put everything into a medical record system, or even writing those notes down by hand. That seemed like the lowest hanging fruit, offering an opportunity to make it easier for doctors that see dozens of patients to make their lives significantly easier, he said.
“We decided we had found a powerful constituency who were burning out because of just documentation,” Soni said. “They have underlying EMR systems that are much older in design. The solution aligns with the commoditization of voice and machine learning. If you put it all together, if we can build a system for doctors and allow doctors to use it in a relatively easy way, they’ll use it to document all the interactions they do with patients. If you have access to all data right from a horse’s mouth, you can use that to solve all the other problems on the health stack.”
The company said it has raised a $15 million funding round led by Venrock, with First Round, Social+Capital, Nat Turner of Flatiron Health, Marc Benioff, and other individual Googlers and angels. Venrock also previously led a $5 million seed financing round, bringing the company’s total funding to around $20 million. It’s also changing its name from Robin AI to Suki, though the reason is actually a pretty simple one: “Suki” is a better wake word for a voice assistant than “Robin” because odds are there’s someone named Robin in the office.
The challenge for a company like Suki is not actually the voice recognition part. Indeed, that’s why Soni said they are actually starting a company like this today: voice recognition is commoditized. Trying to start a company like Suki four years ago would have meant having to build that kind of technology from scratch, but thanks to incredible advances in machine learning over just the past few years, startups can quickly move on to the core business problems they hope to solve rather than focusing on early technical challenges.
Instead, Suki’s problem is one of understanding language. It has to ingest everything that a doctor is saying, parse it, and figure out what goes where in a patient’s documentation. That problem is even more complex because each doctor has a different way of documenting their work with a patient, meaning it has to take extra care in building a system that can scale to any number of doctors. As with any company, the more data it collects over time, the better those results get — and the more defensible the business becomes, because it can be the best product.
“Whether you bring up the iOS app or want to bring it in a website, doctors have it in the exam room,” Soni said. “You can say, ‘Suki, make sure you document this, prescribe this drug, and make sure this person comes back to me for a follow-up visit.’ It takes all that, it captures it into a clinically comprehensive note and then pushes it to the underlying electronic medical record. [Those EMRs] are the system of record, it is not our job to day-one replace these guys. Our job is to make sure doctors and the burnout they are having is relieved.”
Given that voice recognition is commoditized, there will likely be others looking to build a scribe for doctors as well. There are startups like Saykara looking to do something similar, and in these situations it often seems like the companies that are able to capture the most data first are able to become the market leaders. And there’s also a chance that a larger company — like Amazon, which has made its interest in healthcare already known — may step in with its comprehensive understanding of language and find its way into the doctors’ office. Over time, Soni hopes that as it gets more and more data, Suki can become more intelligent and more than just a simple transcription service.
“You can see this arc where you’re going from an Alexa, to a smarter form of a digital assistant, to a device that’s a little bit like a chief resident of a doctor,” Soni said. “You’ll be able to say things like, ‘Suki, pay attention,’ and all it needs to do is listen to your conversation with the patient. I’m, not building a medical transcription company. I’m basically trying to build a digital assistant for doctors.”
Powered by WPeMatico