Startups
Auto Added by WPeMatico
Auto Added by WPeMatico
Credit Karma, which once started as a simple credit report system and is now looking to expand into a true financial assistant, announced today it is getting a massive $500 million secondary investment from Silver Lake.
As part of the investment, Credit Karma says it is getting a 23% bump in the valuation from its last secondary round, which was around $3.25 billion. That means the company is now going to be worth roughly $4 billion altogether, while founder and CEO Kenneth Lin will remain the company’s largest shareholder. That, in the end, is likely important for investors and early employees even as they look to get some liquidity as many look to these founders to ensure that they intend to see the company all the way to the end. Silver Lake’s Mike Bingle is joining the company’s board of directors as part of this deal.
As companies stay private longer, those early employees that spend years at a startup before it hits that huge exit may have to wait longer for some kind of payout for their work. Investors, too, face the same dilemma, especially as the early bets are often just taken on a founder and an idea. And compensation packages early on also typically include equity as a significant portion as companies try to use the financing they raise for growth or other purposes. That makes these kinds of secondary rounds important as it shortens the window for at least some liquidation, which could help employees and investors be a little more patient.
Silver Lake is buying common stock in the company, which is now more than a decade old. But it does mean, with some kind of liquidation for shareholders, that it can likely hold off on an IPO for a little longer. It’s still building out it’s cachet as a financial advisory tool, so it may be that they sought to stay private and not be beholden to the quarterly pressures of a public company while they continue to build out that suite of tools.
Credit Karma is increasingly trying to build a suite of tools that will help it expand just beyond a simple credit score notifier. Late last year, Credit Karma rolled out a tool to be the hub for handling everything related to your cars. All of this sums up to its goal to be a financial assistant, and not just a credit report.
Powered by WPeMatico
It’s easier than ever to build software, which makes it harder than ever to build a defensible software business. So it’s no wonder investors and entrepreneurs are optimistic about the potential of data to form a new competitive advantage. Some have even hailed data as “the new oil.” We invest exclusively in startups leveraging data and AI to solve business problems, so we certainly see the appeal — but the oil analogy is flawed.
In all the enthusiasm for big data, it’s easy to lose sight of the fact that all data is not created equal. Startups and large corporations alike boast about the volume of data they’ve amassed, ranging from terabytes of data to quantities surpassing all of the information contained in the Library of Congress. Quantity alone does not make a “data moat.”
Firstly, raw data is not nearly as valuable as data employed to solve a problem. We see this in the public markets: companies that serve as aggregators and merchants of data, such as Nielsen and Acxiom, sustain much lower valuation multiples than companies that build products powered by data in combination with algorithms and ML, such as Netflix or Facebook. The current generation of AI startups recognize this difference and apply machine learning models to extract value from the data they collect.
Even when data is put to work powering ML-based solutions, the size of the data set is only one part of the story. The value of a data set, the strength of a data moat, comes from context. Some applications require models to be trained to a high degree of accuracy before they can provide any value to a customer, while others need little or no data at all. Some data sets are truly proprietary, others are readily duplicated. Some data decays in value over time, while other data sets are evergreen. The application determines the value of the data.
Machine learning applications can require widely different amounts of data to provide valuable features to the end user.
MAP threshold
In the cloud era, the idea of the minimum viable product (or MVP) has taken hold — that collection of software features which has just enough value to seek initial customers. In the intelligence era, we see the analog emerging for data and models: the minimum level of accurate intelligence required to justify adoption. We call this the minimum algorithmic performance (MAP).
Most applications don’t require 100 percent accuracy to create value. For example, a productivity tool for doctors might initially streamline data entry into electronic health record systems, but over time could automate data entry by learning from what doctors enter in the system. In this case, the MAP is zero, because the application has value from day one based on software features alone. Intelligence can be added later. However, solutions where AI is central to the product (for example, a tool to identify strokes from CT scans), would likely need to equal the accuracy of status quo (human-based) solutions. In this case the MAP is to match the performance of human radiologists, and an immense volume of data might be needed before a commercial launch is viable.
Performance threshold
Not every problem can be solved with near 100 percent accuracy. Some problems are too complex to fully model given the current state of the art; in that case, volume of data won’t be a silver bullet. Adding data might incrementally improve the model’s performance, but quickly hit diminishing marginal returns.
At the other extreme, some problems can be solved with near 100 percent accuracy with a very small training set, because the problem being modeled is relatively simple, with few dimensions to track and few variations in outcome.
In short, the amount of data you need to effectively solve a problem varies widely. We call the amount of training data needed to reach viable levels of accuracy the performance threshold.
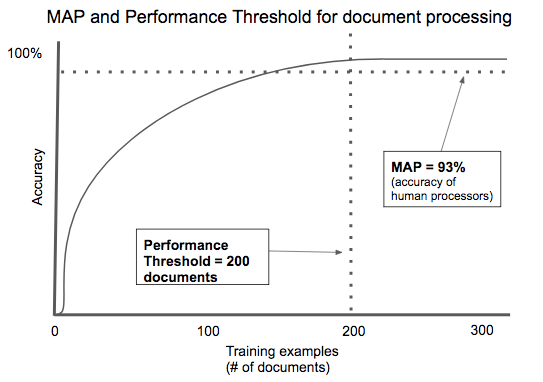 AI-powered contract processing is a good example of an application with a low performance threshold. There are thousands of contract types, but most of them share key fields: the parties involved, the items of value being exchanged, time frame, etc. Specific document types like mortgage applications or rental agreements are highly standardized in order to comply with regulation. Across multiple startups, we’ve seen algorithms that automatically process documents needing only a few hundred examples to train to an acceptable degree of accuracy.
AI-powered contract processing is a good example of an application with a low performance threshold. There are thousands of contract types, but most of them share key fields: the parties involved, the items of value being exchanged, time frame, etc. Specific document types like mortgage applications or rental agreements are highly standardized in order to comply with regulation. Across multiple startups, we’ve seen algorithms that automatically process documents needing only a few hundred examples to train to an acceptable degree of accuracy.
Entrepreneurs need to thread a needle. If the performance threshold is high, you’ll have a bootstrap problem acquiring enough data to create a product to drive customer usage and more data collection. Too low, and you haven’t built much of a data moat!
Stability threshold
Machine learning models train on examples taken from the real-world environment they represent. If conditions change over time, gradually or suddenly, and the model doesn’t change with it, the model will decay. In other words, the model’s predictions will no longer be reliable.
For example, Constructor.io is a startup that uses machine learning to rank search results for e-commerce websites. The system observes customer clicks on search results and uses that data to predict the best order for future search results. But e-commerce product catalogs are constantly changing. A model that weighs all clicks equally, or trained only on a data set from one period of time, risks overvaluing older products at the expense of newly introduced and currently popular products.
Keeping the model stable requires ingesting fresh training data at the same rate that the environment changes. We call this rate of data acquisition the stability threshold.
Perishable data doesn’t make for a very good data moat. On the other hand, ongoing access to abundant fresh data can be a formidable barrier to entry when the stability threshold is low.
The MAP, performance threshold and stability threshold are all central elements to identifying strong data moats.
First-movers may have a low MAP to enter a new category, but once they have created a category and lead it, the minimum bar for future entrants is to equal or exceed the first mover.
Domains requiring less data to reach the performance threshold and less data to maintain that performance (the stability threshold) are not very defensible. New entrants can readily amass enough data and match or leapfrog your solution. On the other hand, companies attacking problems with low performance threshold (don’t require too much data) and a low stability threshold (data decays rapidly) could still build a moat by acquiring new data faster than the competition.
AI investors talk enthusiastically about “public data” versus “proprietary data” to classify data sets, but the strength of a data moat has more dimensions, including:
Software is now a commodity, making data moats more important than ever for companies to build a long-term competitive advantage. With tech titans democratizing access to AI toolkits to attract cloud computing customers, data sets are one of the most important ways to differentiate. A truly defensible data moat doesn’t come from just amassing the largest volume of data. The best data moats are tied to a particular problem domain, in which unique, fresh, data compounds in value as it solves problems for customers.
Powered by WPeMatico
Rumors of a new ASIC mining rig from Bitmain have driven Ethereum prices well below their one-week high of $585. An ASIC – or Application-specific integrated circuit – in the cryptocurrency world is a chip that designers create for the specific purpose of mining a single currency. Early Bitcoin ASICs, for example, drove adoption up and then, in some eyes, centralized Bitcoin mining in a few hands, thereby thwarting the decentralized ethos of die-hard cryptocurrency fans.
According to a CNBC report, analyst Christopher Rolland visited China where he unearthed rumors of a new ASIC chip dedicated to Ethereum mining.
“During our travels through Asia last week, we confirmed that Bitmain has already developed an ASIC [application-specific integrated circuit] for mining Ethereum, and is readying the supply chain for shipments in 2Q18,” analyst Christopher Rolland wrote in a note to clients Monday. “While Bitmain is likely to be the largest ASIC vendor (currently 70-80% of Bitcoin mining ASICs) and the first to market with this product, we have learned of at least three other companies working on Ethereum ASICs, all at various stages of development.”
Historically users have mined Ethereum using GPUs which, in turn, led to the unavailability of GPUs for gaming and graphics. However, an ASIC would change the mining equation entirely, resulting in a certain amount of centralization as big players – including Bitmain – created higher barrier to entry for casual miners.
“Ethereum is of the most profitable coins available for GPU mining,” said Mikhail Avady, founder of TryMining.com. “It’s going to affect a lot of the market. Without understanding the hash power of these Bitmain machines we can’t tell if it will make GPUs obsolete or not.”
“It can be seen as an attack on the network. It’s a centralization problem,” he said.
Avady points out that there is a constant debate among cryptocurrency aficionados regarding ASICs and their effect on the market. Some are expecting a move to more mineable coins including Monero and ZCash.
“What would be bad is if there was only one Ethereum ASIC manufacturer,” he said. “But with Samsung and a couple other players getting into the game it won’t be bad for long.”
There is also concern over ICO launches and actual utility of Ethereum-based smart contract tokens. “The price of ETH is becoming consolidated as people become more realistic about blockchain technology,” said Sky Guo, CEO of Cypherium. “People are looking for higher quality blockchain projects. I believe a rebound in ETH’s price will come soon as panic surrounding regulations begins to fade.”
Powered by WPeMatico
Google will be acquiring Tenor, which powers a variety of GIF keyboards on phones and messengers like Facebook Messenger, the companies announced today.
Tenor will continue to operate as a separate brand within Google, the company said in a blog post. Tenor has increasingly positioned itself as a search company, using that as a metric for engagement and success as users tap into a massive database of GIFs. The company said it has more than 12 billion searches every month, and is one of the first major exits for a small but relatively hot space around tools that allow users to easily share GIFs. The company works with advertisers to create sponsored GIFs that slot into its searches, which are usually pretty compact and offer an opportunity to generate a lot of engagement.
GIFs have increasingly been pretty interesting because they offer an opportunity to compress a lot of information into something that’s easily shareable. Tenor CEO David McIntosh will often say that the company is about conveying emotion — and really, that isn’t something that often goes very well over text. If you’re watching the NCAA Men’s Basketball tournament, you’re probably better off searching for a GIF of your team rather than just blasting a text message to your group of friends.
“With their deep library of content, Tenor surfaces the right GIFs in the moment so you can find the one that matches your mood,” Google Images director of engineering Cathy Edwards said. “Tenor will help us do this more effectively in Google Images as well as other products that use GIFs, like Gboard. Tenor will continue to operate as a separate brand, and we’re looking forward to investing in their technology and relationships with content and API partners. So whether you’re using the Tenor keyboard or one of our other products, you can expect to see much more of this in your future:”
When you open Tenor, you’ll only find a small slice of GIFs that are available as the company is looking to compress the amount of time you actually spending digging around for a GIF you want to share. The theory is that if it’s easier to find and share one, you’ll do it again and again. This isn’t dissimilar from Google’s approach either, offering itself as a utility that’s a quick get-in, get-out experience that builds a level of stickiness that’s hard to unseat. Google is, of course, worth hundreds of billions of dollars off the back of a massive advertising business that basically prints money.
Tenor isn’t the only one in the space. Giphy, for example, also has a GIF keyboard and has a pretty large database of GIFs. Giphy says it has 300 million daily active users, though depending on who you talk to in the Valley that can mean a couple different things. Nevertheless, all of these companies have been able to attract venture financing. There’s also Gfycat, which positions itself as a tool for creators, that says it has 130 million monthly active users.
The terms of the deal weren’t disclosed. But by positioning itself as a search company that slots into a messaging ecosystem, Tenor seems like a natural piece of the puzzle for Google. It also gives the company a small wedge into the messenger space as it’ll have an opportunity to touch all the platforms that are connected to Tenor like even Facebook messenger, though that one tends to flip between GIF platforms indiscriminately.
Powered by WPeMatico
After rocketing to a $250 million valuation in 2015 amid a massive hype cycle for on-demand companies, on-demand startup Shyp is shutting down today.
CEO Kevin Gibbon announced that the company would be shutting down in a blog post this afternoon. The company is ending operations immediately after, like many on-demand companies, struggling to find a scalable model beyond its launching point in San Francisco. Shyp missed targets for expanding to cities beyond its core base as well as pulled back from Miami. In July, Shyp said it would be reducing its headcount and shutting down all operations beyond San Francisco.
The company raised $50 million in a deal led by John Doerr at Kleiner Perkins back in 2015, one of his last huge checks as a variety of firms jumped onto the on-demand space. The thesis at the time was pretty sound: look at a strip mall, and see which businesses can come to you first. Shipping was a natural one, but there was also food, and eventually groceries. Today, there are only a few left standing, with Postmates, Instacart and DoorDash among the most prominent ones. Even then, Instacart is now under threat from Amazon, which is ramping up its own two-hour delivery after buying Whole Foods.
“At the time, I approached everything I did as an engineer,” Gibbon wrote. “Rather than change direction, I tasked the team with expanding geographically and dreaming up innovative features and growth tactics to further penetrate the consumer market. To this day, I’m in awe of the vigor the team possessed in tackling a 200-year-old industry. But, growth at all costs is a dangerous trap that many startups fall into, mine included.”
Shyp is now a casualty of the delivery space. Where it originally sought to make up the cost of delivery in the form of cheaper bulk costs for those deliveries, Shyp’s one-size-fits-all delivery — where you could deliver a computer or a bike — eventually ended up being one of the most challenging and frustrating elements of its business. It began adding fees to its online returns business and changing prices for its bulk shipments. As it turns out, a $5 carte blanche for delivery was not a model that really made sense.
Indeed, that growth-at-all-costs directive has cost many startups, with companies like Sprig shutting down and many companies getting slapped on the wrist for aggressive growth tactics like text spamming. It also meant that startups had to very quickly develop an effective playbook that, in the end, might not actually translate to markets beyond their core competency. Shyp pivoted to focusing on businesses toward the tail end of its lifetime, including a big deal with eBay, which we had heard at the time was doing well.
“We decided to keep the popular-but-unprofitable parts of our business running, with small teams of their own behind them,” he wrote. “This was a mistake—my mistake. While large, established companies have the financial freedom to explore new product categories for the sake of exploring, for startups it can be irresponsible.”
But Gibbon said the company kept parts of its popular but challenged models online – which may have also contributed to its eventual shut-down. The company expected to be in cities like Boston, Seattle and Philadelphia in early 2016, but that didn’t end up panning out. And Shyp increasingly felt the challenges of an on-demand model, trying to push the cost to the consumer as low as possible while handling the overheads and logistical headaches of a delivery business.
“My early mistakes in Shyp’s business ended up being prohibitive to our survival,” Gibbon wrote. “For that, I am sorry.”
Powered by WPeMatico
Yugo is a cool little electric startup from Barcelona that puts a little pep into the streets of that Spanish city. In this fun video we go inside their warehouse workshop to talk about their startup and what it takes to scale a rideshare company from one scooter and forty customers to dozens of scooters and thousands of customers. Interestingly, on the day we shot this video Barcelona had the first snowfall in a decade, making our ride particularly fun – and precarious.
Powered by WPeMatico
What’s the best way to stay up to date on things happening within your industry? Seasoned finance professionals read the Wall Street Journal. Anyone who wants to work in politics reads The Washington Post. In Silicon Valley we have industry-specific news sites like TechCrunch supplemented by Hacker News and others.
But what about young business professionals who either don’t plan on staying in one industry their whole life or just want to stay up to date on the broader business/tech/startups/politics world?
Morning Brew is a daily newsletter designed for young business professionals. Each morning email has a stock market recap, a few short briefs on the most important business news of the day and a small section with lifestyle content. The result is the perfect mix of Wall Street essentials (like market analysis) and tech news (like a deep dive on Y Combinator).
The newsletter, which now has just under 200,000 total subscribers, was founded by Alex Lieberman and Austin Rief in 2015 when they were students at the University of Michigan.
“We worked with more than 75 students to help them prepare for interviews and internships and we’d always ask the question, “How do you keep up with the business world?” It was like every student had rehearsed their answers together beforehand, saying something to the effect of “I read the WSJ…and I read it because it’s a prerequisite to say you’re well-read in business and it’s what my parents do, but it’s dense, dry, and too long to read cover-to-cover,” explained the duo.
So Morning Brew was born. While initially college-focused, that segment has shrunk to 30% of their total audience with the average reader now 28-years-old working in finance, tech, or consulting. Of course there’s nothing stopping an older reader from signing up, and if anything sites like Axios have shown that even non-millennials may now prefer short bullet-point briefings over traditional long-form reporting.
But business-minded millennials are definitely the long-term focus of Morning Brew – and for good reason. The segment is extremely sought after in the advertising world, which has helped the startup monetize early. So far they’ve hosted sponsored native content from brands like Discover Card, Casper and Duke University. The diversity of sponsors shows just how many different industries are trying to reach the demographic.
Similar to other newsletter businesses like theSkimm, Morning Brew has mainly relied on word of mouth referrals and an ambassador program of 700+ students to drive new signups. Total subscribers are nearing 200,000 with a daily open rate hovering around 50%, which for reference is at least double most other popular industry newsletters.
The long term goal is to grow the newsletter into a brand that can touch all aspects of a young professional’s life, including networking. The site is launching a monthly event series this summer to bring together millennials to network and watch panel discussions, which should provide the off-line community building that has proved successful for other media brands.
The startup has raised $750,000 in seed funding from notable media execs including Brian Kelly, founder and CEO of The Points Guy, and is targeting a Series A in 2019.
Powered by WPeMatico
Self-driving technology company Aurora has made some key moves on its leadership team and overall company growth: It’s bringing on SpaceX’s now former head of software engineering, Jinnah Hosein, to lead its own software engineering team in a VP role. The autonomous software provider is also opening up two new offices, including one in San Francisco, and another in Pittsburgh, in addition to its existing HQ in Palo Alto.
Bringing on Hosein is a huge move for Aurora, which will now have some additional senior leadership taken to help direct and organize its growing engineering team, according to Aurora co-founder Chris Urmson . Hosein’s background includes his time as VP of Software Engineering at SpaceX, where he spent the past four years and oversaw projects including the recent successful Falcon Heavy launch. Before that, he was Director of Software Engineering at Google working on Google Cloud, site reliability and other software projects.
“It’s a pretty incredible set of experiences he has,” Urmson said. “We’re just excited about him bringing that leadership capability, that experience in building both cloud and incredibly reliable software to our team and working with the rest of the folks here.”
Hosein also worked for a brief time overseeing Tesla’s software operations as well as SpaceX’s when he served as acting VP of Tesla’s Autopilot Software prior to Tesla hiring Apple’s Chris Lattner for the role. Urmson says that Hosein’s proven track record launching rockets, and organizing software projects on that level of complexity is more important to Aurora than any brief time he may have spent on Autopilot, however.
Aurora is also opening two new physical offices and testing locations, as mentioned, including the San Francisco one that Urmson says will be a welcome relief to some of their employees currently commuting south to Palo Alto, as well as a way to attract more talent looking to work in the city proper. The Pittsburgh office gives them a new testbed, where they can prove their tech in inclement driving conditions and adverse winter weather, and it also puts them in close proximity to Carnegie Mellon and Pittsburgh’s robotics talent pool.
“When you combine that, between the offices we have in the South Bay, the San Francisco test areas that we’ll now have more access to and the Pittsburgh test areas, we have a pretty exciting diversity of test environments and places to operate,” Urmson added.
Aurora has already announced partnerships with Volkswagen, Hyundai, Byton and more, and recently added LinkedIn founder Reid Hoffman and Index Ventures’ Mike Volpi to its board.
Powered by WPeMatico
Owning a Tesla comes with plenty of perks, but there is still one major pain point for most Tesla owners: navigation.
Even though these cars feel like they’re from the future, the navigation systems on board look like any old navigation system you might have seen in a car or on a smartphone, with some of the information in desperate need of an update.
But after promising a navigation update last year, Elon Musk seems to be prepping for its release. Early this morning the Tesla CEO tweeted:
New nav starts rolling out this weekend. Should be considered a mature beta at first, so won’t be perfect, but will improve rapidly. With the old system, we were stuck with legacy 3rd party black box code and stale data. No way to improve.
— Elon Musk (@elonmusk) March 26, 2018
Back in December, Musk said that the new system will be “light-years ahead of current system.”
Musk’s comments on the new nav system suggest that this will go beyond map updates and will instead rethink navigation from top to bottom within Tesla vehicles.
Tesla Maps, as the nav system is called, will roll out this upcoming weekend.
Powered by WPeMatico
After an Ars Technica report that Facebook surreptitiously scrapes call and text message data from Android phones and has done so for years, the scandal-burdened company has responded that it only collects that information from users who have given permission.
Facebook’s public statement, posted on its press site, comes a couple of days after it took out full page newspaper ads to apologize for the misuse of data by third-party apps as it copes with fallout from the Cambridge Analytica scandal (follow the story as it develops here). In the ad, founder and chief executive officer Mark Zuckerberg wrote “We have a responsibility to protect your information. If we can’t, we don’t deserve it.”
The company’s response to the Ars Technica story, however, struck a different tone, with Facebook titling the post “Fact Check: Your Call and SMS History.” It said “You may have seen some recent reports that Facebook has been logging people’s call and SMS (text) history without their permission. This is not the case,” before going on to explain that call and text history logging is included with an opt-in feature on Messenger or Facebook Lite for Android that “people have to expressly agree to use” and that they can turn off at any time, which would also delete any call and text data shared with that app.
Ars Technica has already amended its original post with a response to Facebook’s statement, saying it contradicts several of its findings, including the experience of users who shared their data with the publication.
“In my case, a review of my Google Play data confirms that Messenger was never installed on the Android devices I used,” wrote Ars Technica IT and national security editor Sean Gallagher in the amendment to his post. “Facebook was installed on a Nexus tablet I used and on the Blackphone 2 in 2015, and there was never an explicit message requesting access to phone call and SMS data. Yet there is call data from the end of 2015 until late 2016, when I reinstalled the operating system on the Blackphone 2 and wiped all applications.”
In its statement, Facebook said “Contact importers are fairly common among social apps and services as a way to more easily find the people you want to connect with. This was first introduced in Messenger in 2015, and later offered as an option in Facebook Lite, a lightweight version of Facebook for Android .”
When people first sign up for Messenger or Facebook Lite on Android or log into Messenger on an Android device, they see a screen giving them the option to continuously upload contacts as well as call and text history. Facebook added that on Messenger, users are then given three options: to turn the feature on, “learn more” for more information or “not now” to skip it. On Facebook Lite, they get two options: turn it on or skip. If users who opted in change their minds later, Facebook said they could turn it off in the app’s settings, with the option of turning off continuous call and text history logging while keeping contact uploading enabled or deleting all contact information they’ve uploaded from that app.”

An image included with Facebook’s statement.
Facebook emphasized in bold text that it “never sell this data, and this feature does not collect the content of your text messages or calls.”
Even though the opt-in screens do state that granting permission will “continuously upload info” about contacts and call and text history, it is arguable that many users don’t really understand what that means and that instead of saying “this lets friends find each other on Facebook and helps us create a better experience for everyone” (a message sweetened with a saccharine cartoon of a figure texting a little heart), Facebook should really be giving more details about what exactly will be recorded and why.
With the Cambridge Analytica scandal still fresh on everyone’s minds, Facebook’s apparent willingness to place the onus for protecting personal data on users who already feel victimized is unlikely to help them regain any goodwill. But even people who truly understand the implications of the feature and chose to opt-in anyway did so assuming that their data would be guarded as Facebook promised. As the Cambridge Analytica fiasco threw into sharp relief, that hasn’t always been the case.
Powered by WPeMatico