Enterprise
Auto Added by WPeMatico
Auto Added by WPeMatico
Google is playing catch-up in the cloud, and as such it wants to provide flexibility to differentiate itself from AWS and Microsoft. Today, the company announced a couple of new options to help separate it from the cloud storage pack.
Storage may seem stodgy, but it’s a primary building block for many cloud applications. Before you can build an application you need the data that will drive it, and that’s where the storage component comes into play.
One of the issues companies have as they move data to the cloud is making sure it stays close to the application when it’s needed to reduce latency. Customers also require redundancy in the event of a catastrophic failure, but still need access with low latency. The latter has been a hard problem to solve until today when Google introduced a new dual-regional storage option.
As Google described it in the blog post announcing the new feature, “With this new option, you write to a single dual-regional bucket without having to manually copy data between primary and secondary locations. No replication tool is needed to do this and there are no network charges associated with replicating the data, which means less overhead for you storage administrators out there. In the event of a region failure, we transparently handle the failover and ensure continuity for your users and applications accessing data in Cloud Storage.”
This allows companies to have redundancy with low latency, while controlling where it goes without having to manually move it should the need arise.
Companies don’t always require instant access to data, and Google (and other cloud vendors) offer a variety of storage options, making it cheaper to store and retrieve archived data. As of today, Google is offering a clear way to determine costs, based on customer storage choice types. While it might not seem revolutionary to let customers know what they are paying, Dominic Preuss, Google’s director of product management says it hasn’t always been a simple matter to calculate these kinds of costs in the cloud. Google decided to simplify it by clearly outlining the costs for medium (Nearline) and long-term (Coldline) storage across multiple regions.
As Google describes it, “With multi-regional Nearline and Coldline storage, you can access your data with millisecond latency, it’s distributed redundantly across a multi-region (U.S., EU or Asia), and you pay archival prices. This is helpful when you have data that won’t be accessed very often, but still needs to be protected with geographically dispersed copies, like media archives or regulated content. It also simplifies management.”
Under the new plan, you can select the type of storage you need, the kind of regional coverage you want and you can see exactly what you are paying.
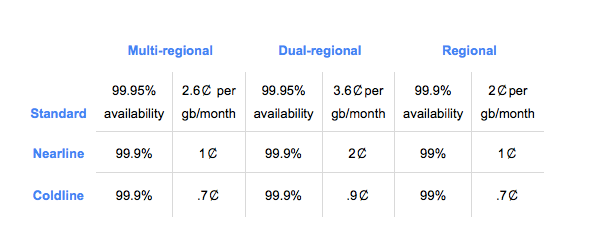
Google Cloud storage pricing options. Chart: Google
Each of these new storage services has been designed to provide additional options for Google Cloud customers, giving them more transparency around pricing and flexibility and control over storage types, regions and the way they deal with redundancy across data stores.
Powered by WPeMatico

Over the course of the last year, Google has launched a number of services that bring to other companies the same BeyondCorp model for managing access to a company’s apps and data without a VPN that it uses internally. Google’s flagship product for this is Cloud Identity, which is essentially Google’s BeyondCorp, but packaged for other businesses.
Today, at its Cloud Next event in London, it’s expanding this portfolio of Cloud Identity services with three new products and features that enable developers to adopt this way of thinking about identity and access for their own apps and that make it easier for enterprises to adopt Cloud Identity and make it work with their existing solutions.
The highlight of today’s announcements, though, is Cloud Identity for Customers and Partners, which is now in beta. While Cloud Identity is very much meant for employees at a larger company, this new product allows developers to build into their own applications the same kind of identity and access management services.
“Cloud Identity is how we protect our employees and you protect your workforce,” Karthik Lakshminarayanan, Google’s product management director for Cloud Identity, said in a press briefing ahead of the announcement. “But what we’re increasingly finding is that developers are building applications and are also having to deal with identity and access management. So if you’re building an application, you might be thinking about accepting usernames and passwords, or you might be thinking about accepting social media as an authentication mechanism.”
This new service allows developers to build in multiple ways of authenticating the user, including through email and password, Twitter, Facebook, their phones, SAML, OIDC and others. Google then handles all of that authentication work. Google will offer both client-side (web, iOS and Android) and server-side SDKs (with support for Node.ja, Java, Python and other languages).
“They no longer have to worry about getting hacked and their passwords and their user credentials getting compromised,” added Lakshminarayanan, “They can now leave that to Google and the exact same scale that we have, the security that we have, the reliability that we have — that we are using to protect employees in the cloud — can now be used to protect that developer’s applications.”
In addition to Cloud Identity for Customers and Partners, Google is also launching a new feature for the existing Cloud Identity service, which brings support for traditional LDAP-based applications and IT services like VPNs to Cloud Identity. This feature is, in many ways, an acknowledgment that most enterprises can’t simply turn on a new security paradigm like BeyondCorp/Cloud Identity. With support for secure LDAP, these companies can still make it easy for their employees to connect to these legacy applications while still using Cloud Identity.
“As much as Google loves the cloud, a mantra that Google has is ‘let’s meet customers where they are.’ We know that customers are embracing the cloud, but we also know that they have a massive, massive footprint of traditional applications,” Lakshminarayanan explained. He noted that most enterprises today run two solutions: one that provides access to their on-premise applications and another that provides the same services for their cloud applications. Cloud Identity now natively supports access to many of these legacy applications, including Aruba Networks (HPE), Itopia, JAMF, Jenkins (Cloudbees), OpenVPN, Papercut, pfSense (Netgate), Puppet, Sophos and Splunk. Indeed, as Google notes, virtually any application that supports LDAP over SSL can work with this new service.
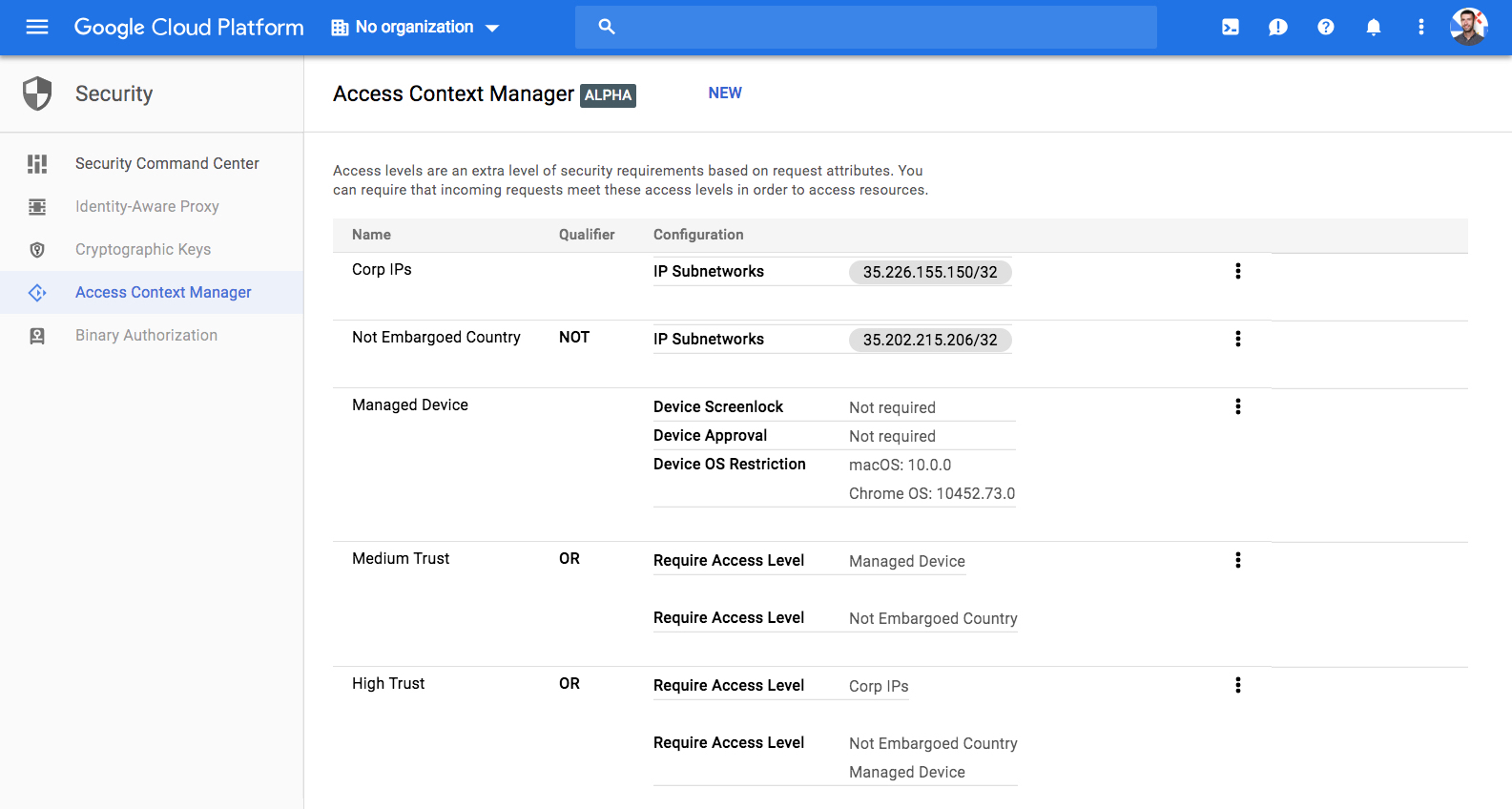
Finally, the third new feature Google is launching today is context-aware access for those enterprises that already use its Cloud Identity-Aware Proxy (yes, those names are all a mouthful). The idea here is to help enterprises provide access to cloud resources based on the identity of the user and the context of the request — all without using a VPN. That’s pretty much the promise of BeyondCorp in a nutshell, and this implementation, which is now in beta, allows businesses to manage access based on the user’s identity and a device’s location and its security status, for example. Using this new service, IT managers could restrict access to one of their apps to users in a specific country, for example.
Powered by WPeMatico

It’s a busy week for news from Google Cloud, which is hosting its Next event in London. Today, the company used the event to launch a number of new networking features. The marquee launch today is Cloud NAT, a new service that makes it easier for developers to build cloud-based services that don’t have public IP addresses and can only be accessed from applications within a company’s virtual private cloud.
As Google notes, building this kind of setup was already possible, but it wasn’t easy. Obviously, this is a pretty common use case, though, so with Cloud NAT, Google now offers a fully managed service that handles all the network address translation (hence the NAT) and provides access to these private instances behind the Cloud NAT gateway.
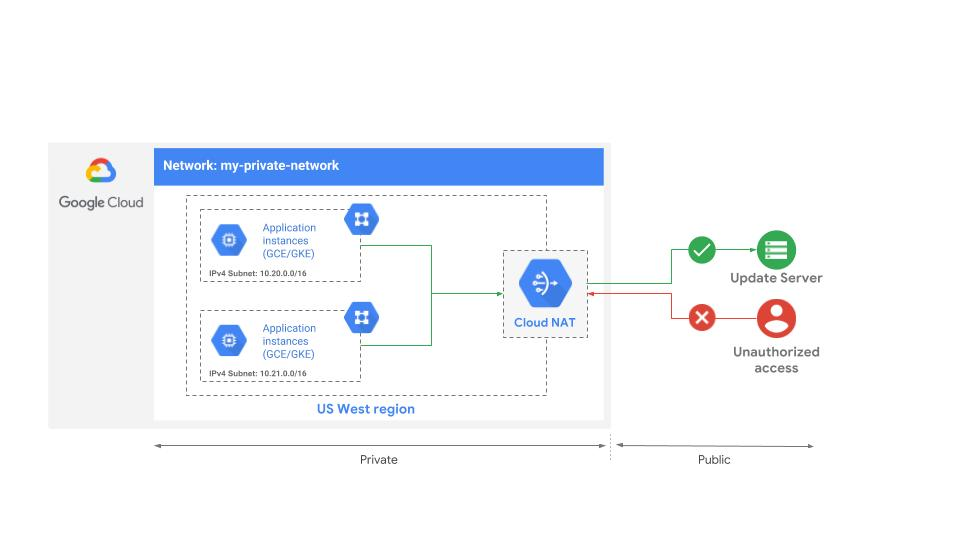
Cloud NAT supports Google Compute Engine virtual machines as well as Google Kubernetes Engine containers, and offers both a manual mode where developers can specify their IPs and an automatic mode where IPs are automatically allocated.
Also new in today’s release is Firewall Rules Logging, which is now in beta. Using this feature, admins can audit, verify and analyze the effects of their firewall rules. That means when there are repeated connection attempts that the firewall blocked, you can now analyze those and see whether somebody was up to no good or whether somebody misconfigured the firewall. Because the data is only delayed by about five seconds, the service provides near real-time access to this data — and you can obviously tie this in with other services like Stackdriver Logging, Cloud Pub/Sub and BigQuery to create alerts and further analyze the data.
Also new today is managed TLS certificated for HTTPS load balancers. The idea here is to take the hassle out of managing TLS certificates (the kind of certificates that ensure that your user’s browser creates a secure connection to your app) when there is a load balancer in play. This feature, too, is now in beta.
Powered by WPeMatico
Enterprise cloud service management company ServiceNow announced today that it will acquire FriendlyData and integrate the startup’s natural language search technology into apps on its Now platform. Founded in 2016, FriendlyData’s natural language query (NLQ) technology enables enterprise customers to build search tools that allow users to ask technical questions even if they don’t know the right jargon.
FriendlyData’s NLQ tech figures out what they are trying to say and then answers with text responses or easy-to-understand data visualizations. ServiceNow said it will integrate FriendlyData’s tech into the Now Platform, which includes apps for IT, human resources, security operations, and customer service management. It will also be available in products for developers and ServiceNow’s partners.
In a statement, Pat Casey, senior vice president of development and operations at ServiceNow, said “ServiceNow is bringing NLQ capabilities to the Now Platform, enabling companies to ask technical questions in plain English and receive direct answers. With this technical enhancement, our goal is to allow anyone to easily make data driven decisions, increasing productivity and driving businesses forward faster.”
The acquisition of FriendlyData is the latest in ServiceNow’s initiative to reduce the friction of support requests within organizations with AI-based tools. For example, it launched a chatbot-building tools called Virtual Agent in May, which enables companies to create custom chatbots for services like Slack or Microsoft Teams to automatically handle routine inquiries such as equipment requests. It also announced the acquisition of Parlo, a chatbot startup, around the same time.
Powered by WPeMatico
Early-stage venture capital firm Shasta Ventures has brought on three new faces to beef up its enterprise software and security portfolio amid a big push to “go deeper” into cybersecurity, per Shasta’s managing director Doug Pepper.
Balaji Yelamanchili (above left), the former general manager and executive vice president of Symantec’s enterprise security business unit, joins as a venture partner on the firm’s enterprise software team. He was previously a senior vice president at Oracle and Dell EMC. Pepper says Yelamanchili will be sourcing investments and may take board seats in “certain cases.”
The firm has also tapped Salesforce’s former chief information security officer Izak Mutlu (above center) as an executive-in-residence, a role in which he’ll advise Shasta portfolio companies. Mutlu spent 11 years at the cloud computing company managing IT security and compliance.
InterWest board partner Drew Harman, the final new hire, has joined as a board partner and will work closely with the chief executive officers of Shasta’s startups. Harman has worked in enterprise software for 25 years across a number of roles. He is currently on the boards of the cloud-based monetization platform Aria, enterprise content marketing startup NewsCred, customer retention software provider Totango and others.
“There’s no area today that’s more important than cybersecurity,” Pepper told TechCrunch. “The business of venture has gotten increasingly competitive and it demands more focus than ever before. We aren’t looking for generalists, we are looking for domain experts.”
Shasta’s security investments include email authentication service Valimail, which raised a $25 million Series B in May. Airspace Systems, a startup that built “kinetic capture” technologies that can identify offending unmanned aircrafts and take them down, raised a $20 million round with participation from Shasta in March. And four-year-old Stealth Security, a startup that defends companies from automated bot attacks, secured an $8 million investment from Shasta in February.
The Menlo Park-based firm filed to raise $300 million for its fifth flagship VC fund in 2016. A year later, it announced a specialty vehicle geared toward augmented and virtual reality app development. With more than $1 billion under management, the firm also backs consumer, IoT, robotics and space-tech companies across the U.S.
In the last year, Shasta has promoted Nikhil Basu Trivedi, Nitin Chopra and Jacob Mullins from associate to partner, as well as added two new associates, Natalie Sandman and Rachel Star.
Powered by WPeMatico

Front is launching a major revamp today. And it starts with a brand new design. Front is now powered by React for the web and desktop app, which should make it easier to add new features down the road.
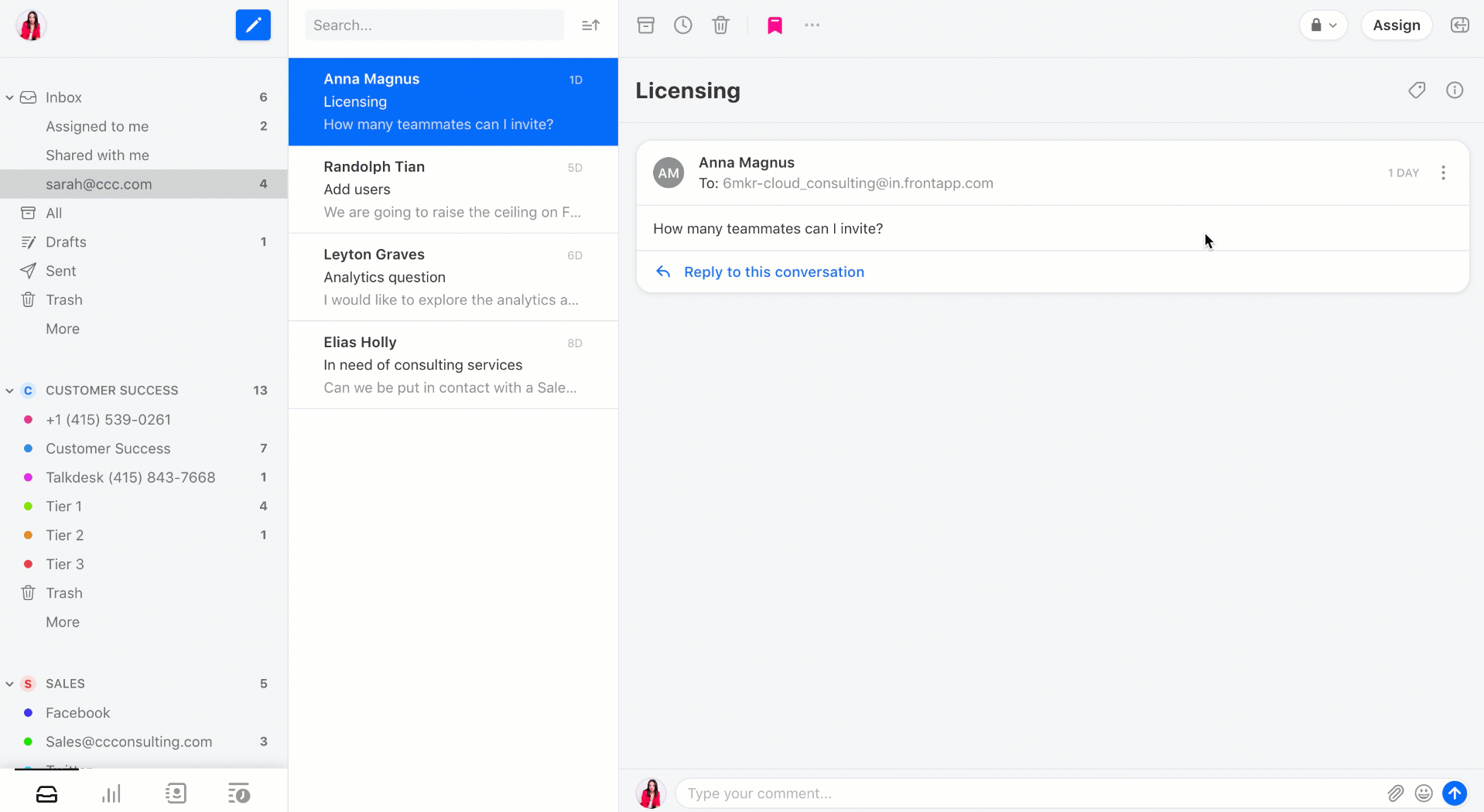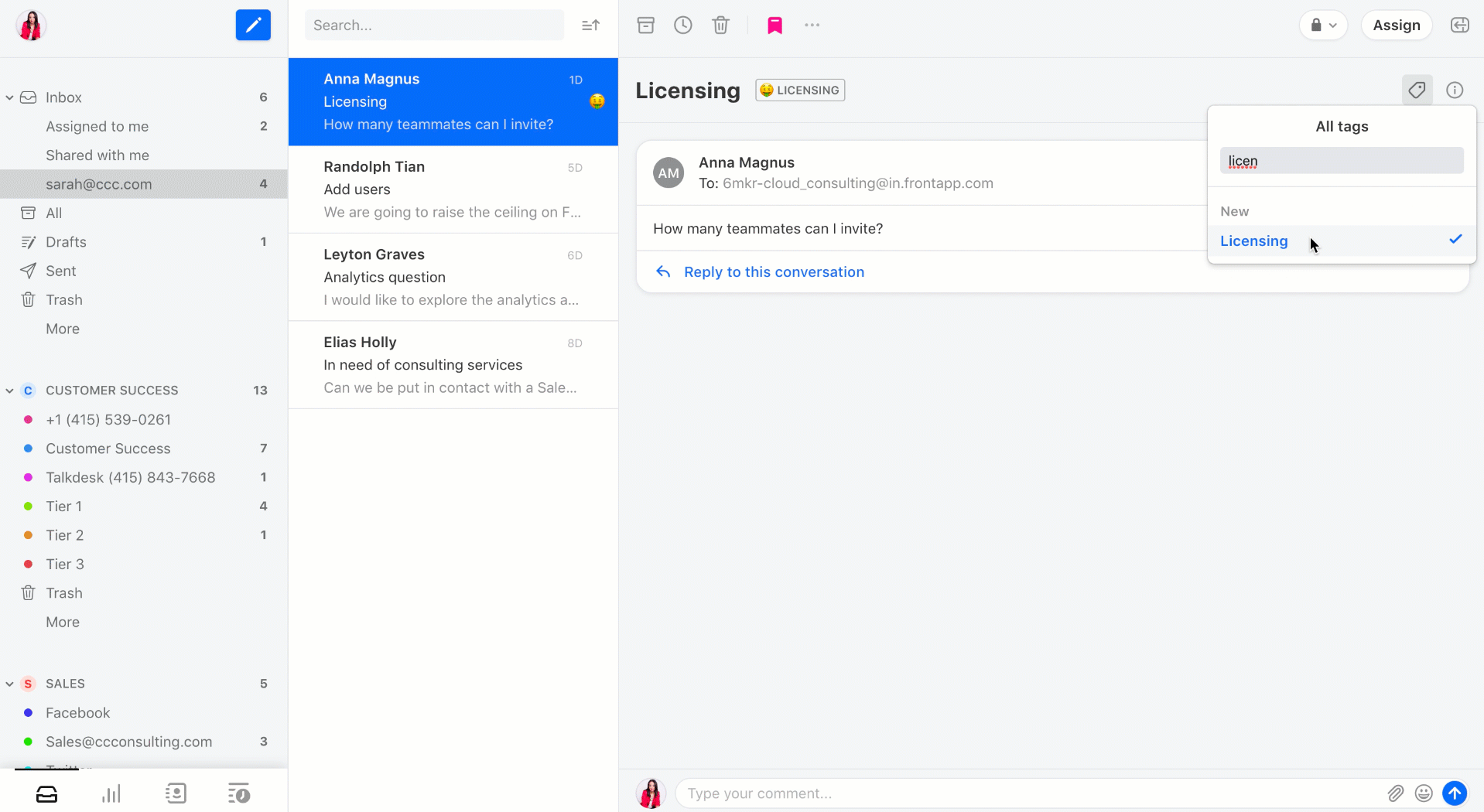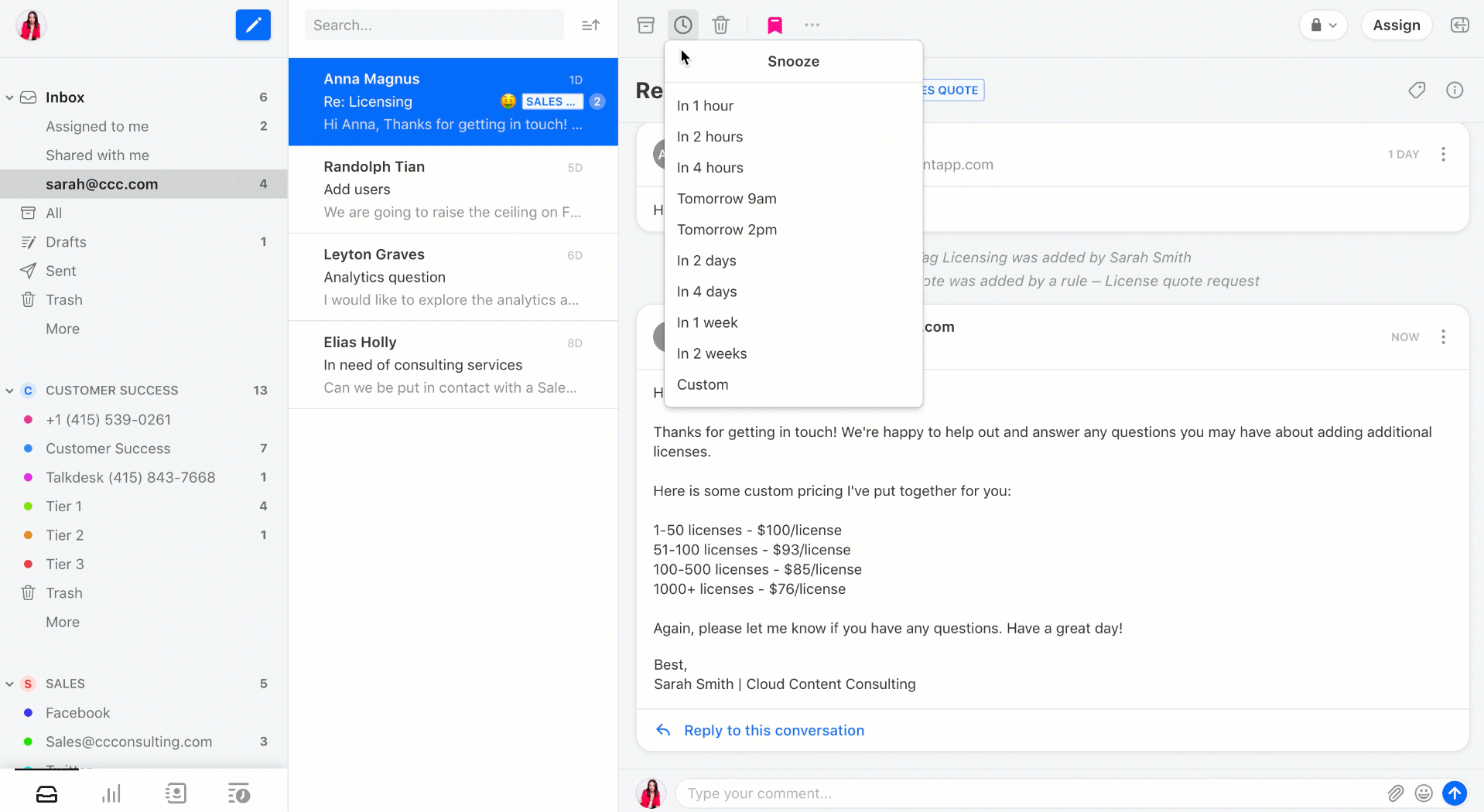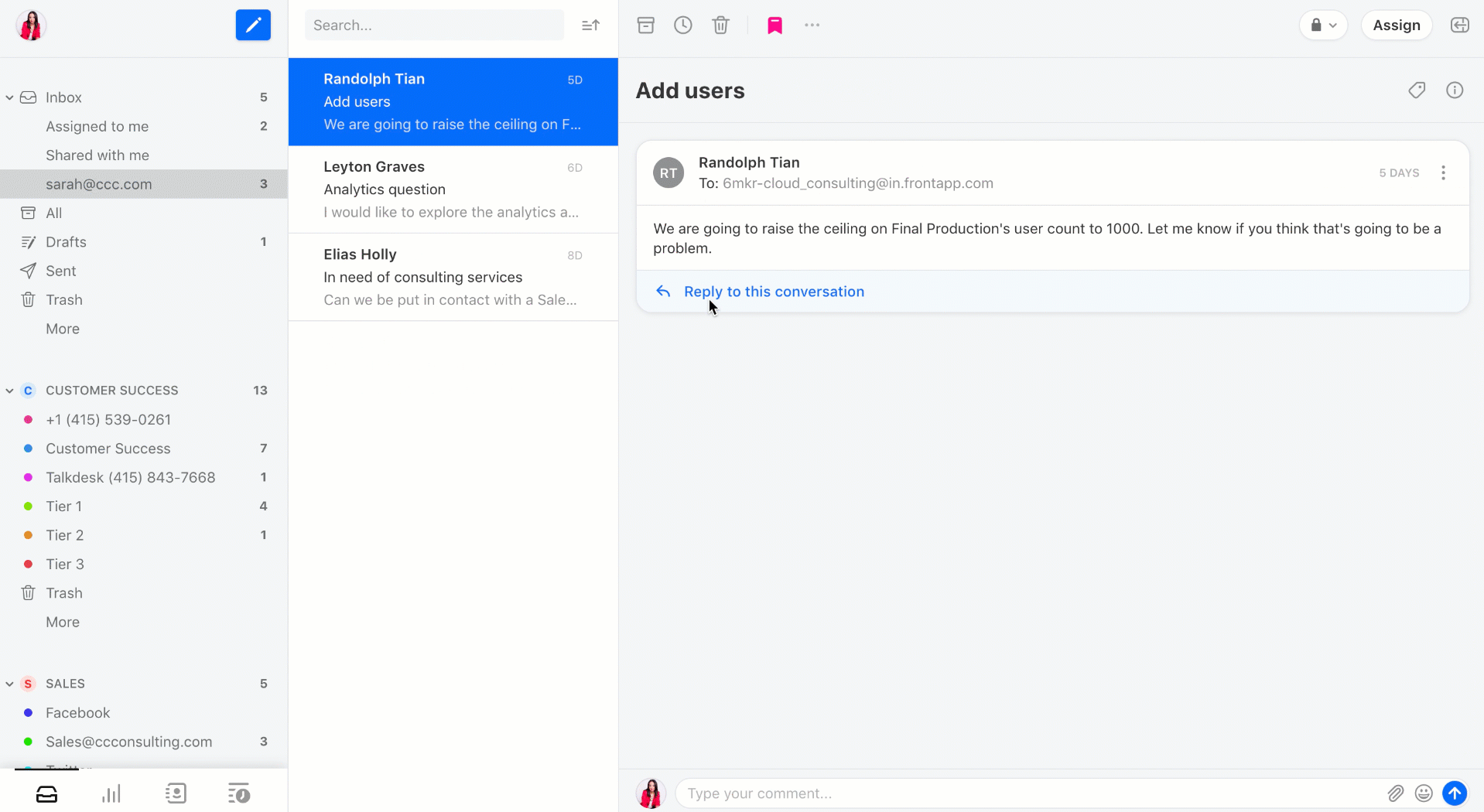
Front hasn’t pivoted to become something else. At heart, it remains a multiplayer email client. You can share generic email addresses with your coworkers, such as sales@yourcompany or jobs@yourcompany. You can then assign emails, comment before replying and integrate your CRM with your email threads.
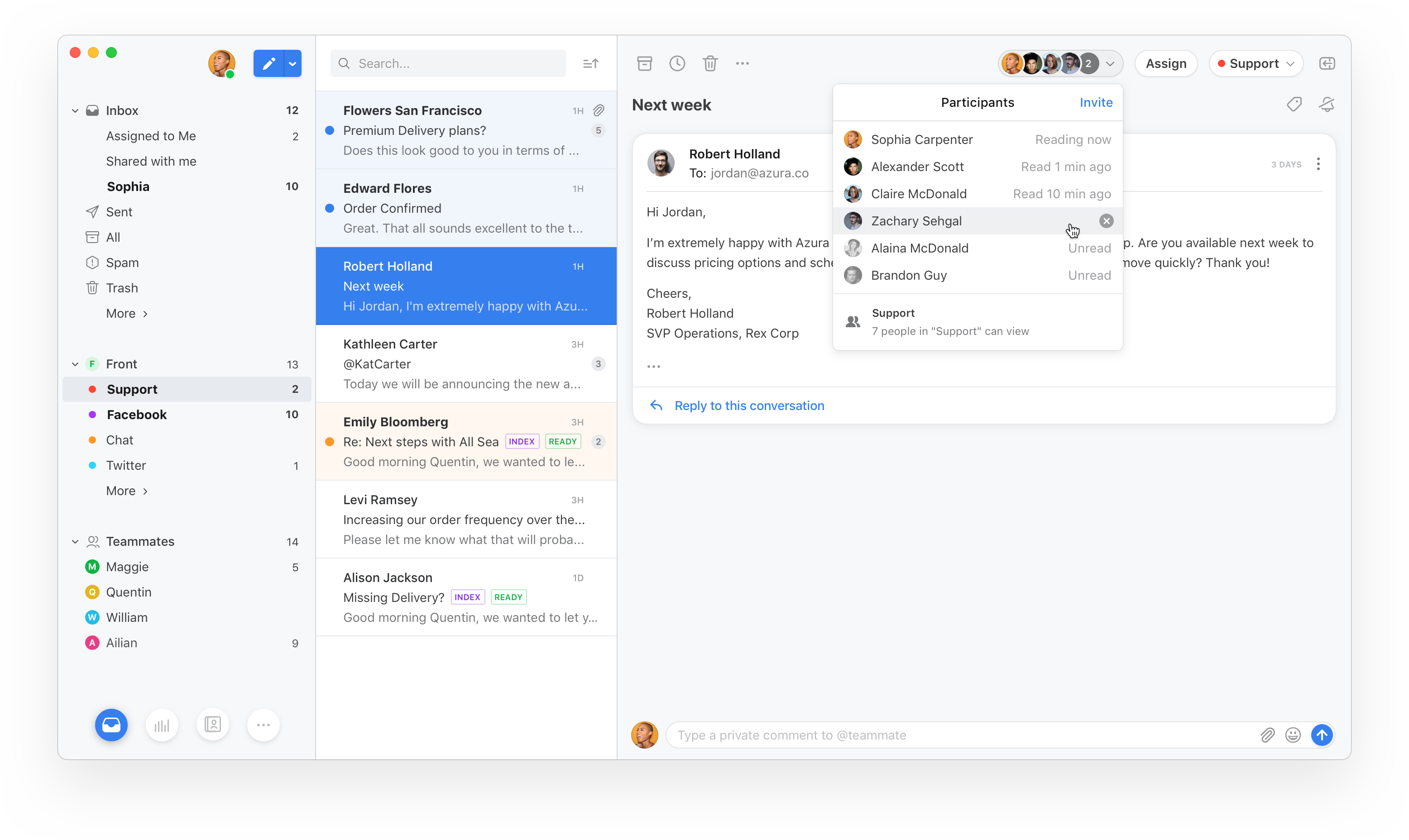
But the company is also adding a bunch of new features. The most interesting one is the ability to start a thread with your team without having to send an email first. If a client sends you an email, you can comment on the thread and mention your coworkers just like on a Facebook post.
Many companies already use emails for internal communications. So they started using Front to talk to their coworkers. Before today, you had to send an original email and then people could comment on it. Now, you can just create a post by giving it a title and jumping to the comment section. It’s much more straightforward.
“We aren’t planning for all internal conversations to move to Front, but a lot of them very well could. A tool like Slack is often used for questions that don’t require the immediate response that Slack demands,” co-founder and CEO Mathilde Collin told me. “By bringing these messages into Front, we aim to reduce disruptions and help people stay focused.”
In other words, a Slack message feels like a virtual tap on the shoulder. You have to interrupt what you’re doing to take a minute and answer. Front can be used for asynchronous conversations and things that don’t need an immediate response. That’s why you can now also send Slack messages to Front so that you can deal with them in Front.
With this update, Front is making sharing more granular. Front isn’t just about shared addresses. You can assign your personal emails to a coworker — this is much more efficient than forwarding an email. Now, you can easily see who can read and interact with an email thread at the top of the email view.
If somebody sends an email to Sarah and Sam, they’ll both have a copy of this email in their personal inboxes. If Sarah and Sam start commenting and @-mentioning people, Front will now merge the threads.
As a user, you get a unified inbox with all your personal emails, emails that were assigned to you and messages assigned to your team inbox.
Finally, Front has improved its smart filtering system. You can now create more flexible rules. For instance, if an email matches some or all criteria, Front can assign an email to a team or a person, send an automated reply, trigger another rule and more.
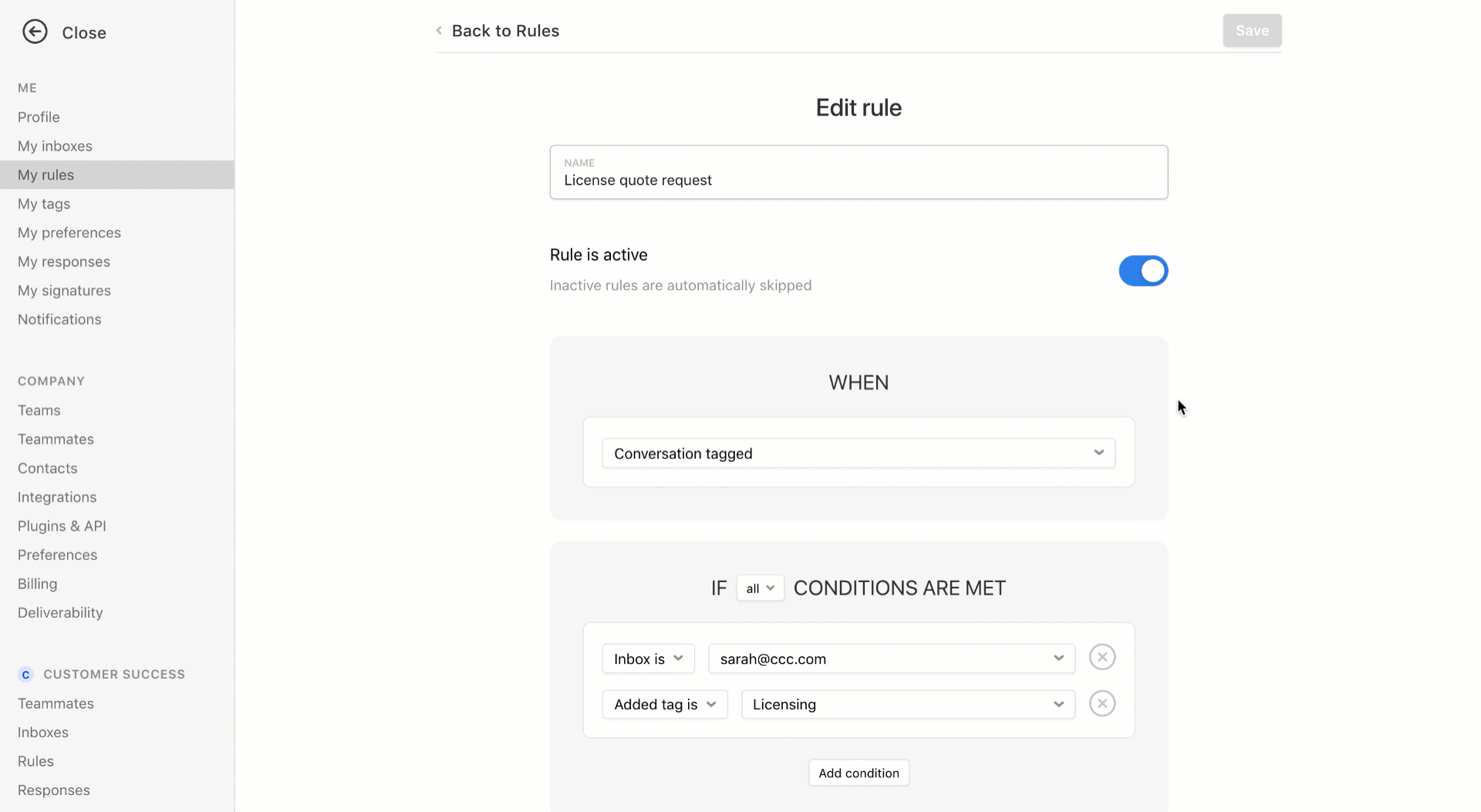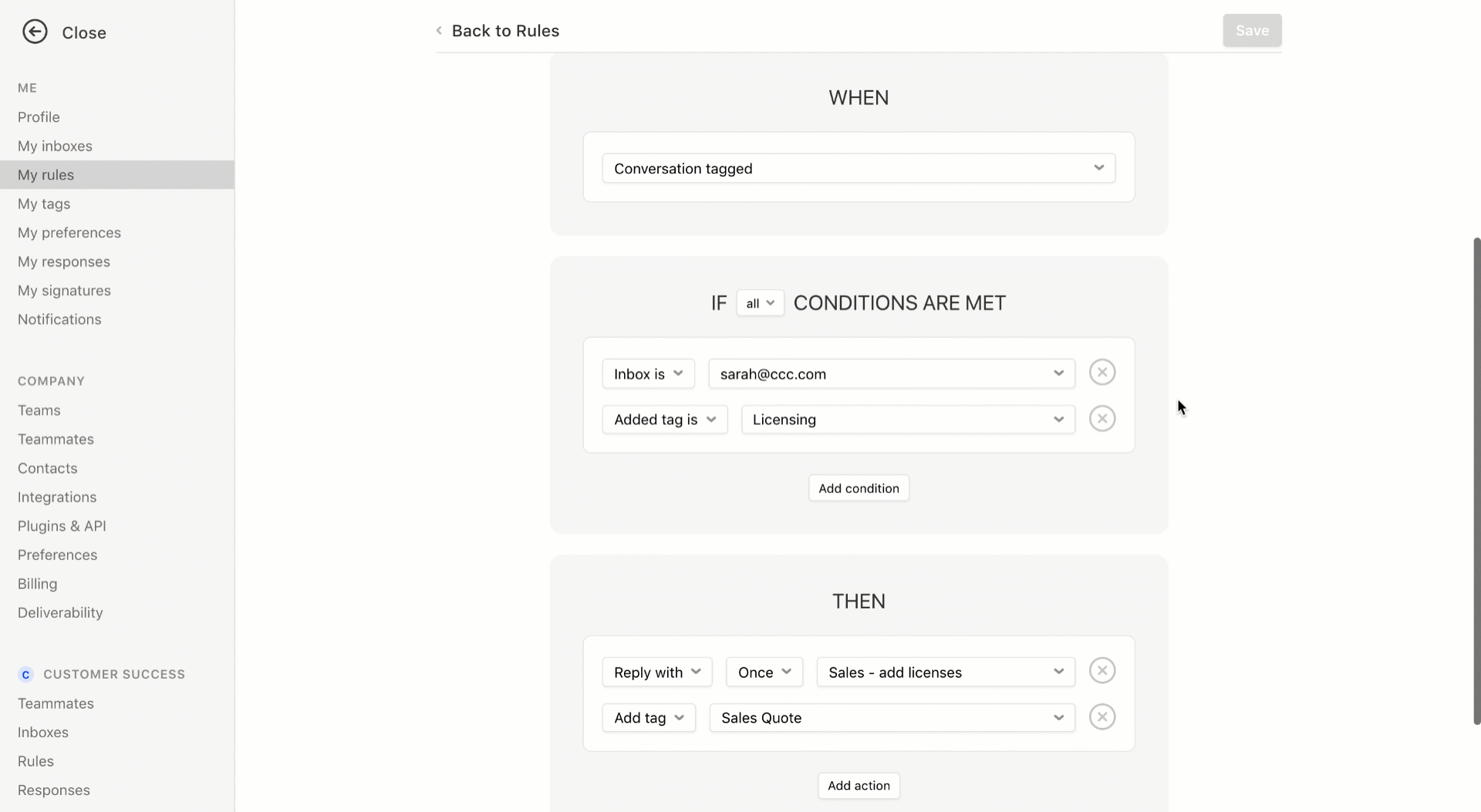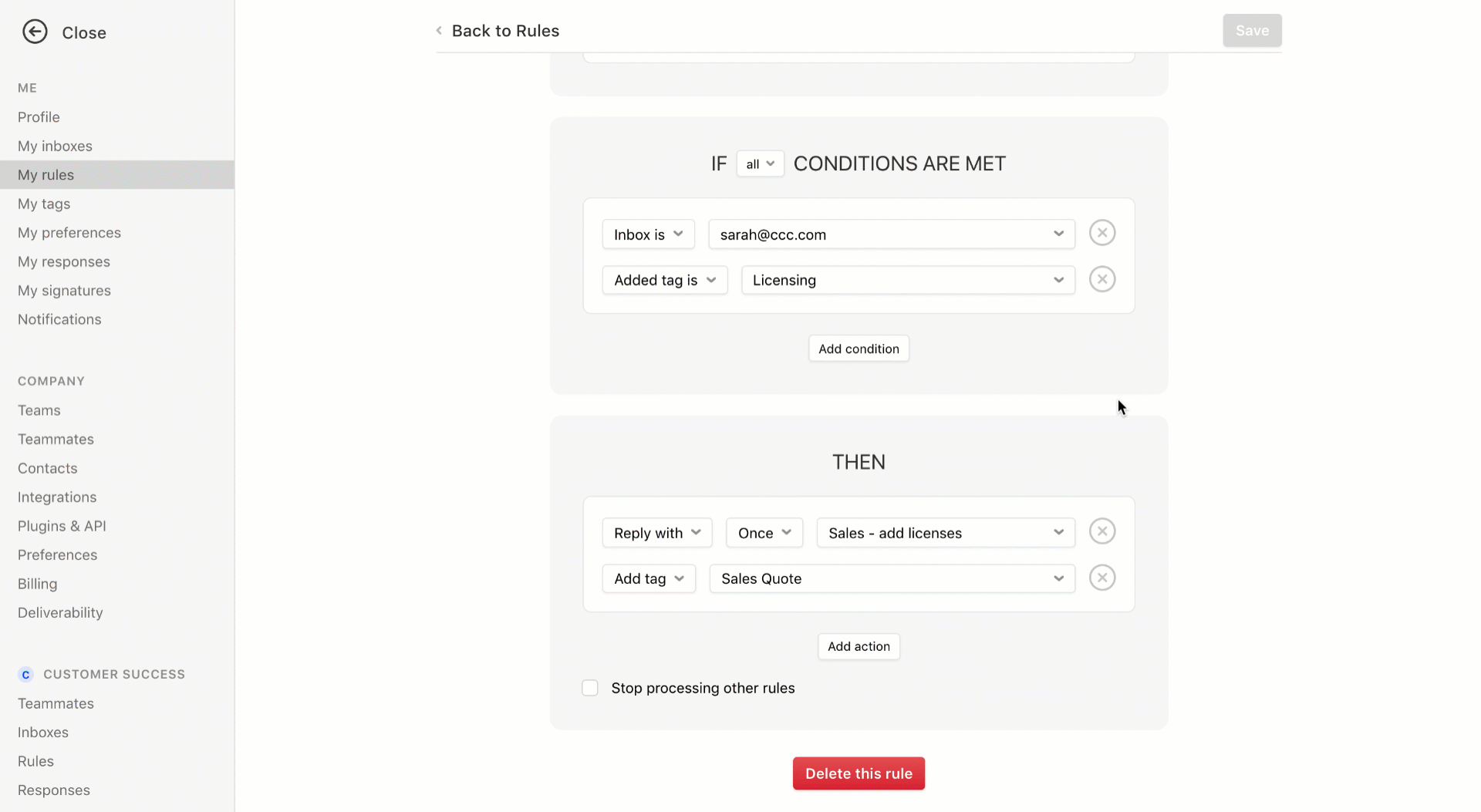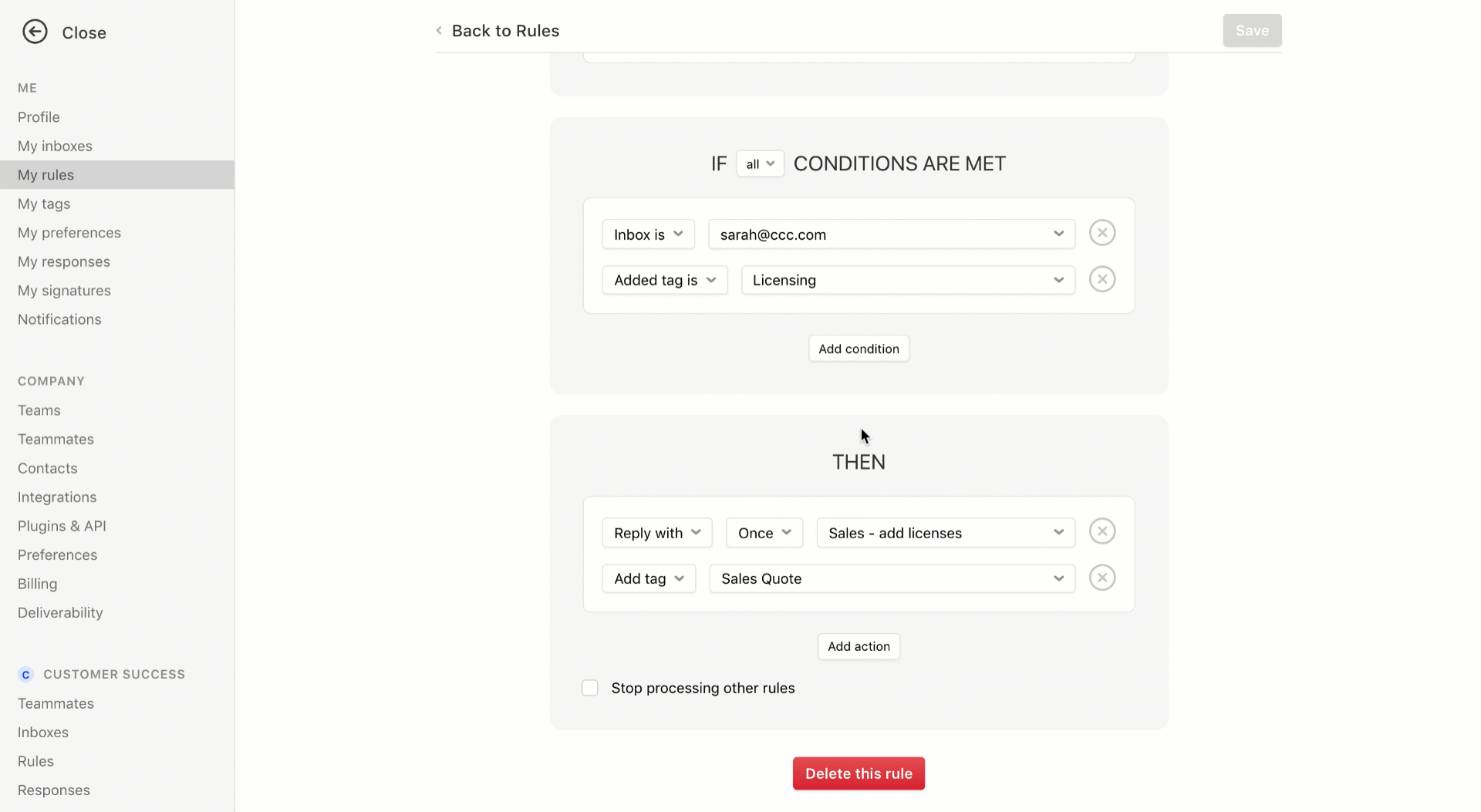
The new version of Front will be available later this month. Once again, Front remains focused on its core mission — making work conversations more efficient and more flexible. The company doesn’t try to reinvent the wheel and still relies heavily on emails.
Many people (myself included) say that email is too often a waste of time. Dealing with emails doesn’t necessarily mean getting work done. Front wants to remove all the pains of this messaging protocol so that you can focus on the content of the messages.
Powered by WPeMatico
Parker Conrad likes to save time, even though it’s gotten him in trouble. The former CEO of Zenefits was pushed out of the $4.5 billion human resources startup because he built a hack that let him and employees get faster insurance certifications. But 2.5 years later, he’s back to take the busy work out of staff onboarding as well as clumsy IT services like single sign-on to enterprise apps. Today his startup Rippling launches its combined employee management system, which Conrad calls a much larger endeavor than the minimum viable product it announced while in Y Combinator’s accelerator 18 months ago.
“It’s not an HR system. It’s a level below that,” Conrad tells me. “It’s this unholy, crazy mashup of three different things.” First, it handles payroll, benefits, taxes and PTO across all 50 states. “Except Syria and North Korea, you can pay anyone in the world with Rippling,” Conrad claims. That makes it a competitor with Gusto… and Zenefits.
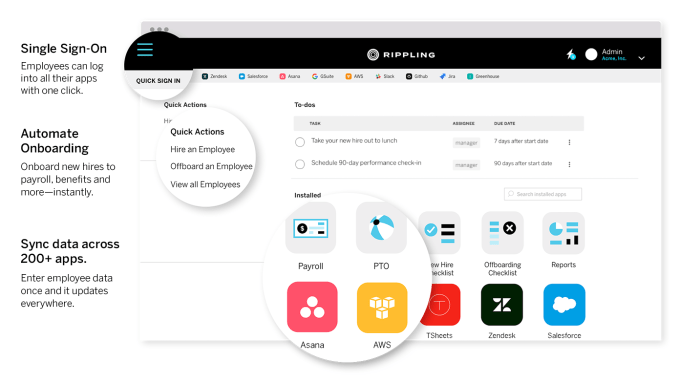
Second, it’s a replacement for Okta, Duo and other enterprise single-sign on security apps that authenticate staffers across partnered apps. Rippling bookmarklets make it easy to auth into over 250 workplace apps, like Gmail, Slack, Dropbox, Asana, Trello, AWS, Salesforce, GitHub and more. When an employee is hired or changes teams, a single modification to their role in Rippling automatically changes all the permissions of what they can access.
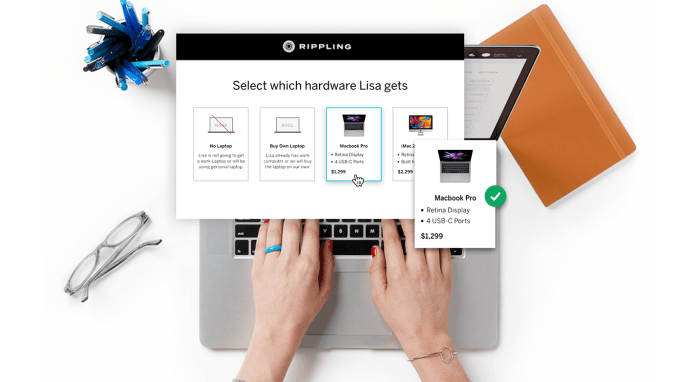
And third, it handles computer endpoint security like Jamf. When an employee is hired, Rippling can instantly ship them a computer with all the right software installed and the hard drive encrypted, or have staffers add the Rippling agent that enforces the company’s security standards. The system is designed so there’s no need for an expert IT department to manage it.
“Distributed, fragmented systems of record for employee data are secretly the cause of almost all the annoying administrative work of running a company,” Conrad explains. “If you could build this system that ties all of it together, you could eliminate all this crap work.” That’s Rippling. It’s opening up to all potential clients today, charging them a combined subscription or à la carte fees for any of the three wings of the product.
Conrad refused to say how much Rippling has raised total, citing the enhanced scrutiny Zenefits’ raises drew. But he says a Wall Street Journal report that Rippling had raised $7 million was inaccurate. “We haven’t raised any priced VC rounds. Just a bunch of seed money. We raised from Initialized Capital, almost all the early seed investors at Zenefits and a lot of individuals.” He cited Y Combinator, YC Growth Fund, YC’s founder Jessica Livingston and president Sam Altman, other YC partners, as well as DFJ and SV Angel.
“Because we were able to raise a bunch of money and court great engineers . . . we were able to spend a lot of time building this fundamental technology,” Conrad tells me. Rippling has about 50 team members now, with about 40 of them being engineers, highlighting just how thoroughly Conrad wants to eradicate manual work about work, starting with his own startup.
The CEO refused to discuss details of exactly what went down at Zenefits and whether he thought his ejection was fair. He was accused of allowing Zenefits’ insurance brokers to sell in states where they weren’t licensed, and giving some employees a macro that let them more quickly pass the online insurance certification exam. Conrad ended up paying about $534,000 in SEC fines. Zenefits laid off 430 employees, or 45 percent of its staff, and moved to selling software to small-to-medium sized businesses through a network of insurance brokers.
But when asked what he’d learned from Zenefits, Conrad looked past those troubles and instead recalled that “one of the mistakes that we made was that we did a lot stuff manually behind the scenes. When you scale up, there are these manual processes, and it’s really hard to come back later when it’s a big hard complicated thing and replace it with technology. You get upside down on margins. If you start at the beginning and never let the manual processes creep in . . . it sort of works.”

Perhaps it was trying to cut corners that got Conrad into the Zenefits mess, but now that same intention has inspired Rippling’s goal of eliminating HR and IT drudgery with an all-in-one tool.
“I think I’m someone who feels the pain of that kind of stuff particularly strongly. So that’s always been a real irritant to me, and I saw this problem. The conventional wisdom is ‘don’t build something like this, start with something much smaller,’ ” Conrad concludes. “But I knew if I didn’t do this, that no one else was gong to do it and I really wanted this system to exist. This is a company that’s all about annoying stuff and making that fucking annoying stuff go away.”
Powered by WPeMatico
Egnyte launched in 2007 just two years after Box, but unlike its enterprise counterpart, which went all-cloud and raised hundreds of millions of dollars, Egnyte saw a different path with a slow and steady growth strategy and a hybrid niche, recognizing that companies were going to keep some content in the cloud and some on prem. Up until today it had raised a rather modest $62.5 million, and hadn’t taken a dime since 2013, but that all changed when the company announced a whopping $75 million investment.
The entire round came from a single investor, Goldman Sachs’ Private Capital Investing arm, a part of Goldman’s Special Situations group. Holger Staude, vice president of Goldman Sachs Private Capital Investing will join Egnyte’s board under the terms of the deal. He says Goldman liked what it saw, a steady company poised for bigger growth with the right influx of capital. In fact, the company has had more than eight straight quarters of growth and have been cash flow positive since Q4 in 2016.
“We were impressed by the strong management team and the company’s fiscal discipline, having grown their top line rapidly without requiring significant outside capital for the past several years. They have created a strong business model that we believe can be replicated with success at a much larger scale,” Staude explained.
Company CEO Vineet Jain helped start the company as a way to store and share files in a business context, but over the years, he has built that into a platform that includes security and governance components. Jain also saw a market poised for growth with companies moving increasing amounts of data to the cloud. He felt the time was right to take on more significant outside investment. He said his first step was to build a list of investors, but Goldman shined through, he said.
“Goldman had reached out to us before we even started the fundraising process. There was inbound interest. They were more aggressive compared to others. Given there was prior conversations, the path to closing was shorter,” he said.
He wouldn’t discuss a specific valuation, but did say they have grown 6x since the 2013 round and he got what he described as “a decent valuation.” As for an IPO, he predicted this would be the final round before the company eventually goes public. “This is our last fund raise. At this level of funding, we have more than enough funding to support a growth trajectory to IPO,” he said.
Philosophically, Jain has always believed that it wasn’t necessary to hit the gas until he felt the market was really there. “I started off from a point of view to say, keep building a phenomenal product. Keep focusing on a post sales experience, which is phenomenal to the end user. Everything else will happen. So this is where we are,” he said.
Jain indicated the round isn’t about taking on money for money’s sake. He believes that this is going to fuel a huge growth stage for the company. He doesn’t plan to focus these new resources strictly on the sales and marketing department, as you might expect. He wants to scale every department in the company including engineering, posts-sales and customer success.
Today the company has 450 employees and more than 14,000 customers across a range of sizes and sectors including Nasdaq, Thoma Bravo, AppDynamics and Red Bull. The deal closed at the end of last month.
Powered by WPeMatico
Nvidia, together with partners like IBM, HPE, Oracle, Databricks and others, is launching a new open-source platform for data science and machine learning today. Rapids, as the company is calling it, is all about making it easier for large businesses to use the power of GPUs to quickly analyze massive amounts of data and then use that to build machine learning models.
“Businesses are increasingly data-driven,” Nvidia’s VP of Accelerated Computing Ian Buck told me. “They sense the market and the environment and the behavior and operations of their business through the data they’ve collected. We’ve just come through a decade of big data and the output of that data is using analytics and AI. But most it is still using traditional machine learning to recognize complex patterns, detect changes and make predictions that directly impact their bottom line.”
The idea behind Rapids then is to work with the existing popular open-source libraries and platforms that data scientists use today and accelerate them using GPUs. Rapids integrates with these libraries to provide accelerated analytics, machine learning and — in the future — visualization.
Rapids is based on Python, Buck noted; it has interfaces that are similar to Pandas and Scikit, two very popular machine learning and data analysis libraries, and it’s based on Apache Arrow for in-memory database processing. It can scale from a single GPU to multiple notes and IBM notes that the platform can achieve improvements of up to 50x for some specific use cases when compared to running the same algorithms on CPUs (though that’s not all that surprising, given what we’ve seen from other GPU-accelerated workloads in the past).
Buck noted that Rapids is the result of a multi-year effort to develop a rich enough set of libraries and algorithms, get them running well on GPUs and build the relationships with the open-source projects involved.
“It’s designed to accelerate data science end-to-end,” Buck explained. “From the data prep to machine learning and for those who want to take the next step, deep learning. Through Arrow, Spark users can easily move data into the Rapids platform for acceleration.”
Indeed, Spark is surely going to be one of the major use cases here, so it’s no wonder that Databricks, the company founded by the team behind Spark, is one of the early partners.
“We have multiple ongoing projects to integrate Spark better with native accelerators, including Apache Arrow support and GPU scheduling with Project Hydrogen,” said Spark founder Matei Zaharia in today’s announcement. “We believe that RAPIDS is an exciting new opportunity to scale our customers’ data science and AI workloads.”
Nvidia is also working with Anaconda, BlazingDB, PyData, Quansight and scikit-learn, as well as Wes McKinney, the head of Ursa Labs and the creator of Apache Arrow and Pandas.
Another partner is IBM, which plans to bring Rapids support to many of its services and platforms, including its PowerAI tools for running data science and AI workloads on GPU-accelerated Power9 servers, IBM Watson Studio and Watson Machine Learning and the IBM Cloud with its GPU-enabled machines. “At IBM, we’re very interested in anything that enables higher performance, better business outcomes for data science and machine learning — and we think Nvidia has something very unique here,” Rob Thomas, the GM of IBM Analytics told me.
“The main benefit to the community is that through an entirely free and open-source set of libraries that are directly compatible with the existing algorithms and subroutines that their used to — they now get access to GPU-accelerated versions of them,” Buck said. He also stressed that Rapids isn’t trying to compete with existing machine learning solutions. “Part of the reason why Rapids is open source is so that you can easily incorporate those machine learning subroutines into their software and get the benefits of it.”
Powered by WPeMatico
Not too long ago, the Cloud Foundry Foundation was all about Cloud Foundry, the open source platform as a service (PaaS) project that’s now in use by most of the Fortune 500 enterprises. This project is the Cloud Foundry Application Runtime. A year ago, the Foundation also announced the Cloud Foundry Container Runtime that helps businesses run the Application Platform and their container-based applications in parallel. In addition, Cloud Foundry has also long been the force behind BOSH, a tool for building, deploying and managing cloud applications.
The addition of the Container Runtime a year go seemed to muddle the organization’s mission a bit, but now that the dust has settled, the intent here is starting to become clearer. As Cloud Foundry CTO Chip Childers told me, what enterprises are mostly using the Container Runtime for is for running the pre-packaged applications they get from their vendors. “The Container Runtime — or really any deployment of Kubernetes — when used next to or in conjunction with the App Runtime, that’s where people are largely landing packaged software being delivered by an independent software vendor,” he told me. “Containers are the new CD-ROM. You just want to land it in a good orchestration platform.”
Because the Application Runtime launched well before Kubernetes was a thing, the Cloud Foundry project built its own container service, called Diego.
 Today, the Cloud Foundry foundation is launching two new Kubernetes-related projects that take the integration between the two to a new level. The first is Project Eirini, which was launched by IBM and is now being worked on by Suse and SAP as well. This project has been a long time in the making and it’s something that the community has expected for a while. It basically allows developers to choose between using the existing Diego orchestrator and Kubernetes when it comes to deploying applications written for the Application Runtime. That’s a big deal for Cloud Foundry.
Today, the Cloud Foundry foundation is launching two new Kubernetes-related projects that take the integration between the two to a new level. The first is Project Eirini, which was launched by IBM and is now being worked on by Suse and SAP as well. This project has been a long time in the making and it’s something that the community has expected for a while. It basically allows developers to choose between using the existing Diego orchestrator and Kubernetes when it comes to deploying applications written for the Application Runtime. That’s a big deal for Cloud Foundry.
“What Eirini does, is it takes that Cloud Foundry Application Runtime — that core PaaS experience that the [Cloud Foundry] brand is so tied to and it allows the underlying Diego scheduler to be replaced with Kubernetes as an option for those use cases that it can cover,” Childers explained. He added that there are still some use cases the Diego container management system is better suited for than Kubernetes. One of those is better Windows support — something that matters quite a bit to the enterprise companies that use Cloud Foundry. Childers also noted that the multi-tenancy guarantees of Kubernetes are a bit less stringent than Diego’s.
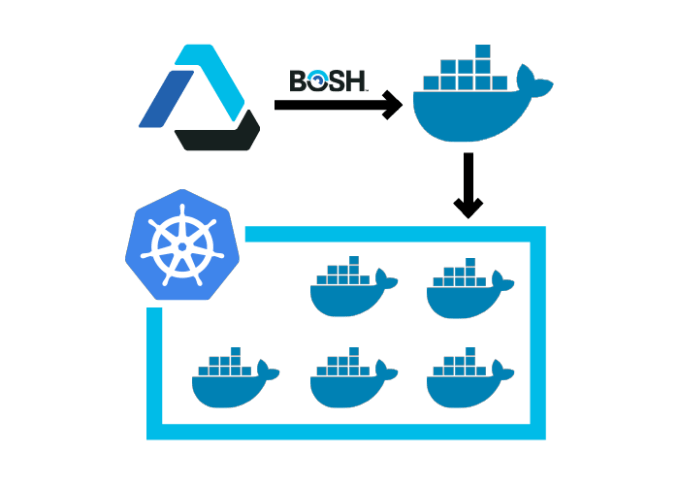 The second new project is CF Containerization, which was initially developed by Suse. Like the name implies, CF Containerization basically allows you to package the core Cloud Foundry Application Runtime and deploy it in Kubernetes clusters with the help of the BOSH deployment tool. This is pretty much what Suse is already using to ship its Cloud Foundry distribution.
The second new project is CF Containerization, which was initially developed by Suse. Like the name implies, CF Containerization basically allows you to package the core Cloud Foundry Application Runtime and deploy it in Kubernetes clusters with the help of the BOSH deployment tool. This is pretty much what Suse is already using to ship its Cloud Foundry distribution.
Clearly then, Kubernetes is becoming part and parcel of what the Cloud Foundry PaaS service will sit on top of and what developers will use to deploy the applications they write for it in the near future. At first glance, this focus on Kubernetes may look like it’s going to make Cloud Foundry superfluous, but it’s worth remembering that, at its core, the Cloud Foundry Application Runtime isn’t about infrastructure but about a developer experience and methodology that aims to manage the whole application development lifecycle. If Kubernetes can be used to help manage that infrastructure, then the Cloud Foundry project can focus on what it does best, too.
Powered by WPeMatico