computing
Auto Added by WPeMatico
Auto Added by WPeMatico
Open source has become a critical building block of modern software, and today a new startup is coming out of stealth to capitalise on one of the newer frontiers in open source: using it to build and manage distributed application environments, an approach being used increasingly to handle large computing projects, such as those involving artificial intelligence or scientific or other complex calculations.
Anyscale, a startup founded by the same team that built the Project Ray open-source distributed programming framework out of UC Berkeley — Robert Nishihara, Philipp Moritz and Ion Stoica, and Berkeley professor Michael I. Jordan — has raised $20.6 million in a Series A round of funding led by Andreessen Horowitz, with participation also from NEA, Intel Capital, Ant Financial, Amplify Partners, 11.2 Capital and The House Fund.
The company plans to use the money to build out its first commercial products — details of which are still being kept under wraps but will more generally include the ability to easily scale out a computing project from one laptop to a cluster of machines; and a group of libraries and applications to manage projects. These are expected to launch next year.
“Right now we are focused on making Ray a standard for building applications,” said Stoica in an interview. “The company will build tools and a runtime platform for Ray. So, if you want to run a Ray application securely and with high performance then you will use our product.”
The funding is partly strategic: Intel is one of the big companies that has been using Ray for its own computing projects, alongside Amazon, Microsoft and Ant Financial.
“Intel IT has been leveraging Ray to scale Python workloads with minimal code modifications,” said Moty Fania, principal engineer and chief technology officer for Intel IT’s Enterprise and Platform Group, in a statement. “With the implementation into Intel’s manufacturing and testing processes, we have found that Ray helps increase the speed and scale of our hyperparameter selection techniques and auto modeling processes used for creating personalized chip tests. For us, this has resulted in reduced costs, additional capacity and improved quality.”
With an impressive user list like this for the free-to-use Ray, you might ask yourself, what is the purpose of Anyscale? As Stoica and Nishihara explained, the idea will be to create simpler and easier ways to implement Ray, to make it usable whether you’re one of the Amazons of the world, or a more modest, and possibly less tech-centric operation.
“We see that this will be valuable mostly for companies who do not have engineering experts,” Stoica said.
The problem that Anyscale is solving is a central one to the future of large-scale, involved computing projects: there are an increasing array of problems that are being tackled with computing solutions, but as the complexity of the work involved increases, there is a limit to how much work a single machine (even a big one) can handle. (Indeed, Anyscale cites IDC figures estimating that the amount of data created and copied annually will reach 175 zettabytes by 2025.)
While one day there may be quantum-computing machines that can run efficiently and at scale to address these kinds of tasks, today this isn’t a realistic option, and so distributed computing has emerged as a solution.
Ray was devised as a standard to use to implement distributed computing environments, but on its own it’s too technical for the uninitiated to use.
“Imagine you’re a biologist,” added Nishihara. “You can write a simple program and run it at a large scale, but to do that successfully you need not only to be a biology expert but a computing expert. That’s just way too high a barrier.”
The people behind Anyscale (and Ray) have a long and very credible list of other work behind them that speaks to the opportunities that are being spotted here. Stoica, for example, was also the co-founder of Databricks, Conviva and one of the original developers of Apache Spark.
“I worked on Databricks with Ion and that’s how it started,” Andreessen Horowitz co-founder Ben Horowitz said in an interview. He added that the firm has been a regular investor into projects coming out of UC Berkeley. Ray, and more specifically Anyscale, is notable for its relevance to today’s computing needs.
“With Ray it was a very attractive project because of the open-source metrics but also because of the issue it addresses,” he said.
“We’ve been grappling with Moore’s Law being over, but more interestingly, it’s inadequate for things like artificial intelligence applications,” where increasing computing power is needed that outstrips what any single machine can do. “You have to be able to deal with distributed computing, but the problem for everyone but Google is that distributed computing is hard, so we have been looking for a solution.”
Powered by WPeMatico

The amount of data that most companies now store — and the places they store it — continues to increase rapidly. With that, the risk of the wrong people managing to get access to this data also increases, so it’s no surprise that we’re now seeing a number of startups that focus on protecting this data and how it flows between clouds and on-premises servers. Satori Cyber, which focuses on data protecting and governance, today announced that it has raised a $5.25 million seed round led by YL Ventures.
“We believe in the transformative power of data to drive innovation and competitive advantage for businesses,” the company says. “We are also aware of the security, privacy and operational challenges data-driven organizations face in their journey to enable broad and optimized data access for their teams, partners and customers. This is especially true for companies leveraging cloud data technologies.”
Satori is officially coming out of stealth mode today and launching its first product, the Satori Cyber Secure Data Access Cloud. This service provides enterprises with the tools to provide access controls for their data, but maybe just as importantly, it also offers these companies and their security teams visibility into their data flows across cloud and hybrid environments. The company argues that data is “a moving target” because it’s often hard to know how exactly it moves between services and who actually has access to it. With most companies now splitting their data between lots of different data stores, that problem only becomes more prevalent over time and continuous visibility becomes harder to come by.

“Until now, security teams have relied on a combination of highly segregated and restrictive data access and one-off technology-specific access controls within each data store, which has only slowed enterprises down,” said Satori Cyber CEO and co-founder Eldad Chai. “The Satori Cyber platform streamlines this process, accelerates data access and provides a holistic view across all organizational data flows, data stores and access, as well as granular access controls, to accelerate an organization’s data strategy without those constraints.”
Both co-founders (Chai and CTO Yoav Cohen) previously spent nine years building security solutions at Imperva and Incapsula (which acquired Imperva in 2014). Based on this experience, they understood that onboarding had to be as easy as possible and that operations would have to be transparent to the users. “We built Satori’s Secure Data Access Cloud with that in mind, and have designed the onboarding process to be just as quick, easy and painless. On-boarding Satori involves a simple host name change and does not require any changes in how your organizational data is accessed or used,” they explain.
Powered by WPeMatico
Cisco today announced that it has acquired Exablaze, an Australia-based company that designs and builds advanced networking gear based on field programmable gate arrays (FPGAs). The company focuses on solutions for businesses that need ultra-low latency networking, with a special emphasis on high-frequency trading. Cisco plans to integrate Exablaze’s technology into its own product portfolio.
“By adding Exablaze’s segment leading ultra-low latency devices and FPGA-based applications to our portfolio, financial and HFT customers will be better positioned to achieve their business objectives and deliver on their customer value proposition,” writes Cisco’s head of corporate development Rob Salvagno.
Founded in 2013, Exablaze has offices in Sydney, New York, London and Shanghai. While financial trading is an obvious application for its solutions, the company also notes that it has users in the big data analytics, high-performance computing and telecom space.
Cisco plans to add Exablaze to its Nexus portfolio of data center switches. The company also argues that in addition to integrating Exablaze’s current portfolio, the two companies will work on next-generation switches, with an emphasis on creating opportunities for expanding its solutions into AI and ML segments.
“The acquisition will bring together Cisco’s global reach, extensive sales and support teams, and broad technology and manufacturing base, with Exablaze’s cutting-edge low-latency networking, layer 1 switching, timing and time synchronization technologies, and low-latency FPGA expertise,” explains Exablaze co-founder and chairman Greg Robinson.
Cisco, which has always been quite acquisitive, has now made six acquisitions this year. Most of these were software companies, but with Acacia Communications, it also recently announced its intention to acquire another fabless semiconductor company that builds optical interconnects.
Powered by WPeMatico
BMW today announced that it is finally bringing Android Auto to its vehicles, starting in July 2020. With that, it will join Apple’s CarPlay in the company’s vehicles.
The first live demo of Android Auto in a BMW will happen at CES 2020 next month. After that, it will become available as an update to drivers in 20 countries with cars that feature the BMW OS 7.0. BMW will support Android Auto over a wireless connection, though, which somewhat limits its comparability.
Only two years ago, the company said that it wasn’t interested in supporting Android Auto. At the time, Dieter May, who was then the senior VP for Digital Services and Business Model, explicitly told me that the company wanted to focus on its first-party apps in order to retain full control over the in-car interface and that he wasn’t interested in seeing Android Auto in BMWs. May has since left the company, though it’s also worth noting that Android Auto itself has become significantly more polished over the course of the last two years.
“The Google Assistant on Android Auto makes it easy to get directions, keep in touch and stay productive. Many of our customers have pointed out the importance to them of having Android Auto inside a BMW for using a number of familiar Android smartphone features safely without being distracted from the road, in addition to BMW’s own functions and services,” said Peter Henrich, senior vice president Product Management BMW, in today’s announcement.
With this, BMW will also finally offer support for the Google Assistant after early bets on Alexa, Cortana and the BMW Assistant (which itself is built on top of Microsoft’s AI stack). The company has long said it wants to offer support for all popular digital assistants. For the Google Assistant, the only way to make that work, at least for the time being, is Android Auto.
In BMWs, Android Auto will see integrations into the car’s digital cockpit, in addition to BMW’s Info Display and the heads-up display (for directions). That’s a pretty deep integration, which goes beyond what most car manufacturers feature today.
“We are excited to work with BMW to bring wireless Android Auto to their customers worldwide next year,” said Patrick Brady, vice president of engineering at Google. “The seamless connection from Android smartphones to BMW vehicles allows customers to hit the road faster while maintaining access to all of their favorite apps and services in a safer experience.”
Powered by WPeMatico
Data breaches that could cause millions of dollars in potential damages have been the bane of the life of many a company. What’s required is a great deal of real-time monitoring. The problem is that this world has become incredibly complex. A SANS Institute survey found half of company data breaches were the result of account or credential hacking.
GitGuardian has attempted to address this with a highly developer-centric cybersecurity solution.
It’s now attracted the attention of major investors, to the tune of $12 million in Series A funding, led by Balderton Capital . Scott Chacon, co-founder of GitHub, and Solomon Hykes, founder of Docker, also participated in the round.
The startup plans to use the investment from Balderton Capital to expand its customer base, predominantly in the U.S. Around 75% of its clients are currently based in the U.S., with the remainder being based in Europe, and the funding will continue to drive this expansion.
Built to uncover sensitive company information hiding in online repositories, GitGuardian says its real-time monitoring platform can address the data leaks issues. Modern enterprise software developers have to integrate multiple internal and third-party services. That means they need incredibly sensitive “secrets,” such as login details, API keys and private cryptographic keys used to protect confidential systems and data.
GitGuardian’s systems detect thousands of credential leaks per day. The team originally built its launch platform with public GitHub in mind; however, GitGuardian is built as a private solution to monitor and notify on secrets that are inappropriately disseminated in internal systems as well, such as private code repositories or messaging systems.
Solomon Hykes, founder of Docker and investor at GitGuardian, said: “Securing your systems starts with securing your software development process. GitGuardian understands this, and they have built a pragmatic solution to an acute security problem. Their credentials monitoring system is a must-have for any serious organization.”
Do they have any competitors?
Co-founder Jérémy Thomas told me: “We currently don’t have any direct competitors. This generally means that there’s no market, or the market is too small to be interesting. In our case, our fundraise proves we’ve put our hands on something huge. So the reason we don’t have competitors is because the problem we’re solving is counterintuitive at first sight. Ask any developer, they will say they would never hardcode any secret in public source code. However, humans make mistakes and when that happens, they can be extremely serious: it can take a single leaked credential to jeopardize an entire organization. To conclude, I’d say our real competitors so far are black hat hackers. Black hat activity is real on GitHub. For two years, we’ve been monitoring organized groups of hackers that exchange sensitive information they find on the platform. We are competing with them on speed of detection and scope of vulnerabilities covered.”
Powered by WPeMatico

AWS today quietly brought spot capacity to Fargate, its serverless compute engine for containers that supports both the company’s Elastic Container Service and, now, its Elastic Kubernetes service.
Like spot instances for the EC2 compute platform, Fargate Spot pricing is significantly cheaper, both for storage and compute, than regular Fargate pricing. In return, though, you have to be able to accept the fact that your instance may get terminated when AWS needs additional capacity. While that means Fargate Spot may not be perfect for every workload, there are plenty of applications that can easily handle an interruption.
“Fargate now has on-demand, savings plan, spot,” AWS VP of Compute Services Deepak Singh told me. “If you think about Fargate as a compute layer for, as we call it, serverless compute for containers, you now have the pricing worked out and you now have both orchestrators on top of it.”
He also noted that containers already drive a significant percentage of spot usage on AWS in general, so adding this functionality to Fargate makes a lot of sense (and may save users a few dollars here and there). Pricing, of course, is the major draw here and an hour of CPU time on Fargate Spot will only cost $0.01245364 (yes, AWS is pretty precise there) compared to $0.04048 for the on-demand price,
With this, AWS is also launching another important new feature: capacity providers. The idea here is to automate capacity provisioning for Fargate and EC2, both of which now offer on-demand and spot instances, after all. You simply write a config file that, for example, says you want to run 70 percent of your capacity on EC2 and the rest on spot instances. The scheduler will then keep that capacity on spot as instances come and go, and if there are no spot instances available, it will move it to on-demand instances and back to spot once instances are available again.
In the future, you will also be able to mix and match EC2 and Fargate. “You can say, I want some of my services running on EC2 on demand, some running on Fargate on demand, and the rest running on Fargate Spot,” Singh explained. “And the scheduler manages it for you. You squint hard, capacity is capacity. We can attach other capacity providers.” Outpost, AWS’ fully managed service for running AWS services in your data center, could be a capacity provider, for example.
These new features and prices will be officially announced in Thursday’s re:Invent keynote, but the documentation and pricing is already live today.

Powered by WPeMatico

You’ve probably heard murmurs about Google’s forthcoming Ambient Mode for Android . The company first announced this feature, which essentially turns an Android device into a smart display while it’s charging, in September. Now, in a Twitter post, Google confirmed that it will launch soon, starting with a number of select devices that run Android 8.0 or later.
At the time, Google said Ambient Mode was coming to the Lenovo Smart Tab M8 HD and Smart Tab tablets, as well as the Nokia 7.2 and 6.2 phones. According to the Verge, it’ll also come to Sony, Nokia, Transsion and Xiaomi phones, though Google’s own Pixels aren’t on the company’s list yet.
While your
charges, Ambient Mode comes to life. Hear how it delivers a proactive Google Assistant experience to your #Android phone. pic.twitter.com/67rrgTTxqO
— Android (@Android) November 25, 2019
“The ultimate goal for proactive Assistant is to help you get things done faster, anticipate your needs and accomplish your tasks as quickly and as easily as possible,” said Google Assistant product manager Arvind Chandrababu in the announcement. “It’s fundamentally about moving from an app-based way of doing things to an intent-based way of doing things. Right now, users can do most things with their smartphones, but it requires quite a bit of mental bandwidth to figure out, hey, I need to accomplish this task, so let me backtrack and figure out all the steps that I need to do in order to get there.”
Those are pretty lofty goals. In practice, what this means, for now, is that you will be able to set an alarm with just a few taps from the ambient screen, see your upcoming appointments, turn off your connected lights and see a slideshow of your images in the background. I don’t think that any of those tasks really consumed a lot of mental bandwidth in the first place, but Google says it has more proactive experiences planned for the future.
Powered by WPeMatico
AWS today announced a number of IoT-related updates that, for the most part, aim to make getting started with its IoT services easier, especially for companies that are trying to deploy a large fleet of devices. The marquee announcement, however, is about the Alexa Voice Service, which makes Amazon’s Alex voice assistant available to hardware manufacturers who want to build it into their devices. These manufacturers can now create “Alexa built-in” devices with very low-powered chips and 1MB of RAM.
Until now, you needed at least 100MB of RAM and an ARM Cortex A-class processor. Now, the requirement for Alexa Voice Service integration for AWS IoT Core has come down 1MB and a cheaper Cortex-M processor. With that, chances are you’ll see even more lightbulbs, light switches and other simple, single-purpose devices with Alexa functionality. You obviously can’t run a complex voice-recognition model and decision engine on a device like this, so all of the media retrieval, audio decoding, etc. is done in the cloud. All it needs to be able to do is detect the wake word to start the Alexa functionality, which is a comparably simple model.
“We now offload the vast majority of all of this to the cloud,” AWS IoT VP Dirk Didascalou told me. “So the device can be ultra dumb. The only thing that the device still needs to do is wake word detection. That still needs to be covered on the device.” Didascalou noted that with new, lower-powered processors from NXP and Qualcomm, OEMs can reduce their engineering bill of materials by up to 50 percent, which will only make this capability more attractive to many companies.
Didascalou believes we’ll see manufacturers in all kinds of areas use this new functionality, but most of it will likely be in the consumer space. “It just opens up the what we call the real ambient intelligence and ambient computing space,” he said. “Because now you don’t need to identify where’s my hub — you just speak to your environment and your environment can interact with you. I think that’s a massive step towards this ambient intelligence via Alexa.”
No cloud computing announcement these days would be complete without talking about containers. Today’s container announcement for AWS’ IoT services is that IoT Greengrass, the company’s main platform for extending AWS to edge devices, now offers support for Docker containers. The reason for this is pretty straightforward. The early idea of Greengrass was to have developers write Lambda functions for it. But as Didascalou told me, a lot of companies also wanted to bring legacy and third-party applications to Greengrass devices, as well as those written in languages that are not currently supported by Greengrass. Didascalou noted that this also means you can bring any container from the Docker Hub or any other Docker container registry to Greengrass now, too.
“The idea of Greengrass was, you build an application once. And whether you deploy it to the cloud or at the edge or hybrid, it doesn’t matter, because it’s the same programming model,” he explained. “But very many older applications use containers. And then, of course, you saying, okay, as a company, I don’t necessarily want to rewrite something that works.”
Another notable new feature is Stream Manager for Greengrass. Until now, developers had to cobble together their own solutions for managing data streams from edge devices, using Lambda functions. Now, with this new feature, they don’t have to reinvent the wheel every time they want to build a new solution for connection management and data retention policies, etc., but can instead rely on this new functionality to do that for them. It’s pre-integrated with AWS Kinesis and IoT Analytics, too.
Also new for AWS IoT Greengrass are fleet provisioning, which makes it easier for businesses to quickly set up lots of new devices automatically, as well as secure tunneling for AWS IoT Device Management, which makes it easier for developers to remote access into a device and troubleshoot them. In addition, AWS IoT Core now features configurable endpoints.
Powered by WPeMatico
Cloud Foundry, the open-source platform-as-a-service that, with the help of lots of commercial backers, is currently in use by the majority of Fortune 500 companies, launched well before containers, and especially the Kubernetes orchestrator, were a thing. Instead, the project built its own container service, but the rise of Kubernetes obviously created a lot of interest in using it for managing Cloud Foundry’s container implementation. To do so, the organization launched Project Eirini last year; today, it’s officially launching version 1.0, which means it’s ready for production usage.
Eirini/Kubernetes doesn’t replace the old architecture. Instead, for the foreseeable future, they will operate side-by-side, with the operators deciding on which one to use.
The team working on this project shipped a first technical preview earlier this year and a number of commercial vendors, too, started to build their own commercial products around it and shipped it as a beta product.
 “It’s one of the things where I think Cloud Foundry sometimes comes at things from a different angle,” IBM’s Julz Friedman told me. “Because it’s not about having a piece of technology that other people can build on in order to build a platform. We’re shipping the end thing that people use. So 1.0 for us — we have to have a thing that ticks all those boxes.”
“It’s one of the things where I think Cloud Foundry sometimes comes at things from a different angle,” IBM’s Julz Friedman told me. “Because it’s not about having a piece of technology that other people can build on in order to build a platform. We’re shipping the end thing that people use. So 1.0 for us — we have to have a thing that ticks all those boxes.”
He also noted that Diego, Cloud Foundry’s existing container management system, had been battle-tested over the years and had always been designed to be scalable to run massive multi-tenant clusters.
“If you look at people doing similar things with Kubernetes at the moment,” said Friedman, “they tend to run lots of Kubernetes clusters to scale to that kind of level. And Kubernetes, although it’s going to get there, right now, there are challenges around multi-tenancy, and super big multi-tenant scale”
But even without being able to get to this massive scale, Friedman argues that you can already get a lot of value even out of a small Kubernetes cluster. Most companies don’t need to run enormous clusters, after all, and they still get the value of Cloud Foundry with the power of Kubernetes underneath it (all without having to write YAML files for their applications).
As Cloud Foundry CTO Chip Childers also noted, once the transition to Eirini gets to the point where the Cloud Foundry community can start applying less effort to its old container engine, those resources can go back to fulfilling the project’s overall mission, which is about providing the best possible developer experience for enterprise developers.
“We’re in this phase in the industry where Kubernetes is the new infrastructure and [Cloud Foundry] has a very battle-tested developer experience around it,” said Childers. “But there’s also really interesting ideas that are out there that are coming from our community, so one of the things that I’ve suggested to the community writ large is, let’s use this time as an opportunity to not just evolve what we have, but also make sure that we’re paying attention to new workflows, new models, and figure out what’s going to provide benefit to that enterprise developer that we’re so focused on — and bring those types of capabilities in.”
Those new capabilities may be around technologies like functions and serverless, for example, though Friedman at least is more focused on Eirini 1.1 for the time being, which will include closing the gaps with what’s currently available in Cloud Foundry’s old scheduler, like Docker image support and support for the Cloud Foundry v3 API.
Powered by WPeMatico

Google Cloud today announced the launch of a new bare metal service, dubbed the Bare Metal Solution. We aren’t talking about bare metal servers offered directly by Google Cloud here, though. Instead, we’re talking about a solution that enterprises can use to run their specialized workloads on certified hardware that’s co-located in the Google Cloud data centers and directly connect them to Google Cloud’s suite of other services. The main workload that makes sense for this kind of setup is databases, Google notes, and specifically Oracle Database.
Bare Metal Solution is, as the name implies, a fully integrated and fully managed solution for setting up this kind of infrastructure. It involves a completely managed hardware infrastructure that includes servers and the rest of the data center facilities like power and cooling; support contracts with Google Cloud and billing are handled through Google’s systems, as well as an SLA. The software that’s deployed on those machines is managed by the customer — not Google.
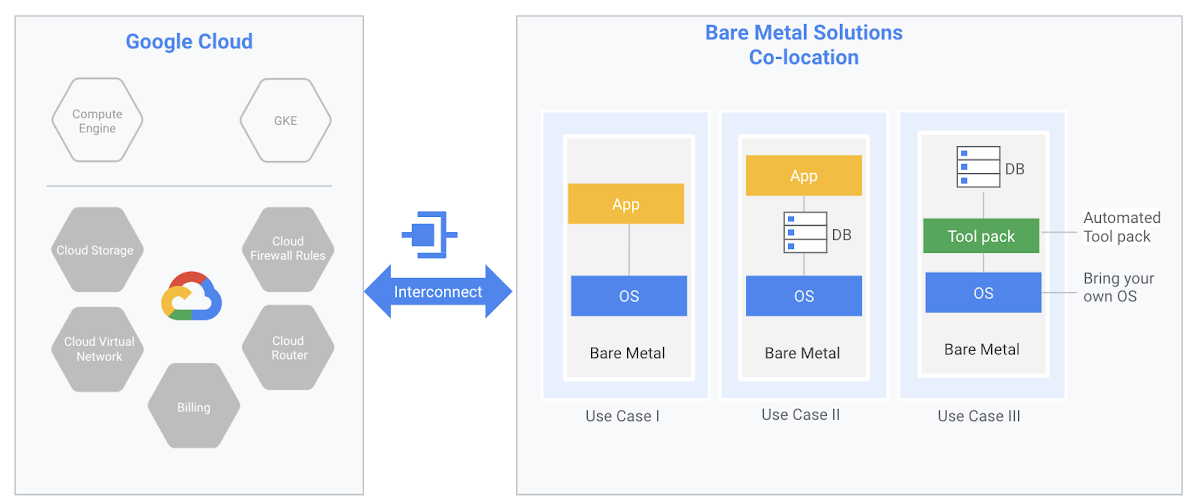
The overall idea, though, is clearly to make it easier for enterprises with specialized workloads that can’t easily be migrated to the cloud to still benefit from the cloud-based services that need access to the data from these systems. Machine learning is an obvious example, but Google also notes that this provides these companies with a bridge to slowly modernize their tech infrastructure in general (where “modernize” tends to mean “move to the cloud”).
“These specialized workloads often require certified hardware and complicated licensing and support agreements,” Google writes. “This solution provides a path to modernize your application infrastructure landscape, while maintaining your existing investments and architecture. With Bare Metal Solution, you can bring your specialized workloads to Google Cloud, allowing you access and integration with GCP services with minimal latency.”
Because this service is co-located with Google Cloud, there are no separate ingress and egress charges for data that moves between Bare Metal Solution and Google Cloud in the same region.
The servers for this solution, which are certified to run a wide range of applications (including Oracle Database) range from dual-socket 16-core systems with 384 GB of RAM to quad-socket servers with 112 cores and 3072 GB of RAM. Pricing is on a monthly basis, with a preferred term length of 36 months.
Obviously, this isn’t the kind of solution that you self-provision, so the only way to get started — and get pricing information — is to talk to Google’s sales team. But this is clearly the kind of service that we should expect from Google Cloud, which is heavily focused on providing as many enterprise-ready services as possible.
Powered by WPeMatico